Google Patents an Ad-Targeting System That Predicts Whether You'll Actually Pay Attention
Google wants to stop serving ads that users will immediately ignore. A newly filed patent describes a system that predicts whether you'll actually register an ad before deciding to show it to you.
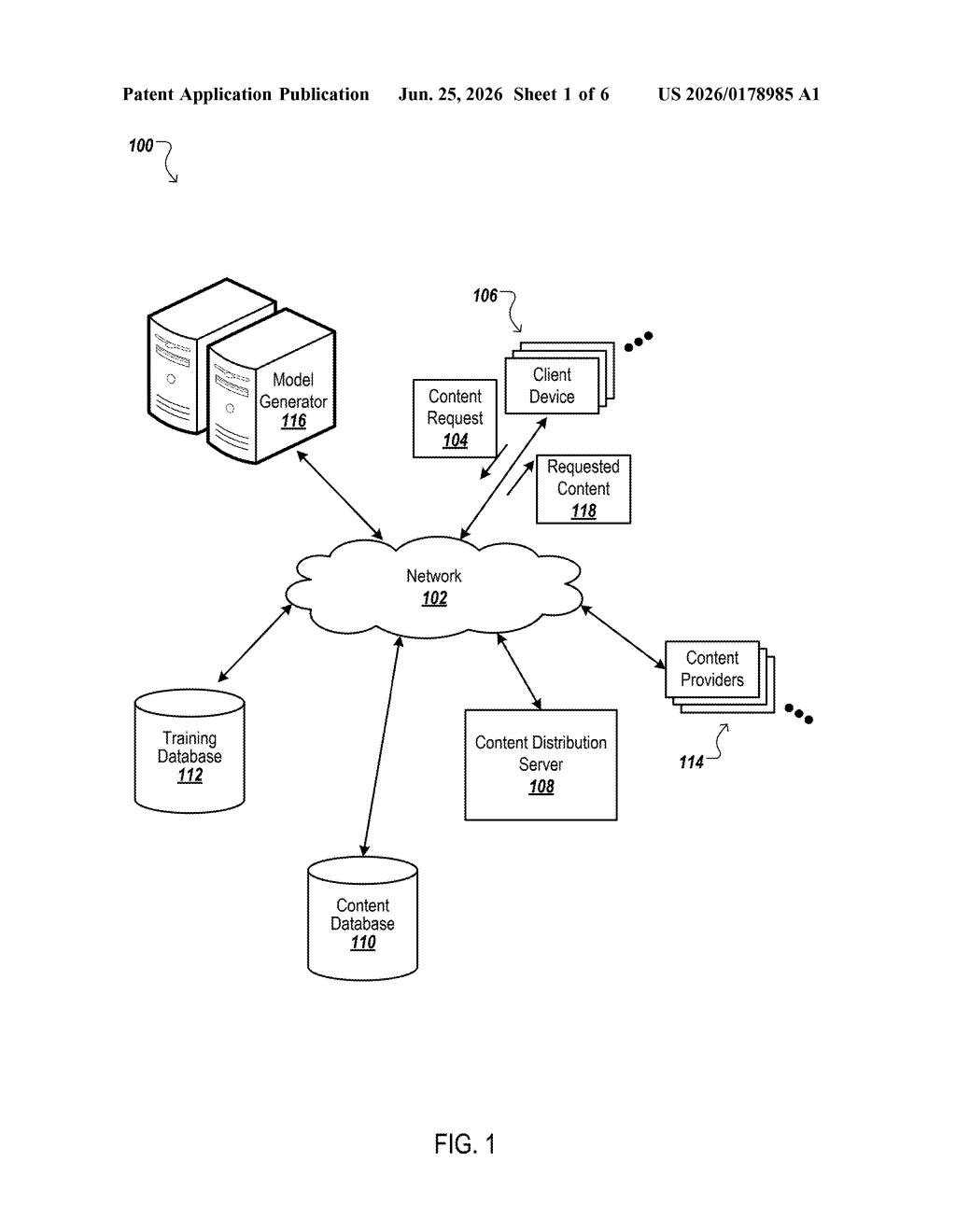
How Google's attention-prediction ad model works
Imagine you're reading an article and an ad pops up. Most of the time, your eyes slide right past it. Google's ad business depends on those ads working, so there's a real incentive to get better at predicting when an ad will actually stick.
This patent describes a system where a machine-learning model is trained on past user behavior: what people did after seeing certain ads. The model learns to predict, for any given ad, whether showing it to a particular person will result in them actually noticing or remembering it. These predictions are called "proxy metrics" because they stand in for the outcomes advertisers really care about, like brand awareness or continued engagement.
Before your device gets served an ad, this system checks those predicted scores against a threshold. Only ads that cross the bar get selected. Think of it as a filter that sits between the ad auction and your screen asking: "Is this ad even worth showing?"
Inside the proxy-metric model and training pipeline
The system has four main components working together:
- Training database: Stores historical data linking user attributes (demographics, browsing context, etc.) to proxy metrics, measurable signals of behavior after an ad was shown, such as whether a user stayed on the page or showed signs of brand recall.
- Content database: A catalog of third-party ads from various advertisers.
- Model generator: Trains a predictive model using that historical data. The model learns which combinations of user attributes and ad characteristics tend to produce strong proxy metrics.
- Content distribution server: When a page requests an ad to show alongside its content, this server runs the model in real time. It pulls the user's attributes from the request, evaluates candidate ads, predicts a proxy metric for each, and selects only those that meet a defined threshold.
The key idea is the proxy metric, a computed stand-in for harder-to-measure outcomes like "did the user become aware of this brand?" or "did they stick around long enough to absorb the message?" Training on those proxies lets the model optimize for something more meaningful than raw clicks.
The threshold mechanism means the system can be configured to be more or less selective, depending on whether the goal is maximizing volume or maximizing quality of impressions.
What this means for advertisers and your ad feed
For advertisers, this is a pitch that Google's ad inventory is higher quality because the system filters out impressions that predictive data says won't land. That's the kind of argument that justifies premium pricing and wins over brand-focused buyers who care about awareness, not just clicks.
For you as a user, it means the ads you see are increasingly selected based on a model's prediction of your attention, not just your past purchases or search history. The inputs are your "attributes," a broad term that in practice could include almost anything Google knows about you. Whether that leads to more relevant ads or just more precisely profiled ones is a question the patent doesn't answer.
This is core ad-tech infrastructure work, not a flashy product reveal. But it matters because it shows Google investing in attention-quality signals rather than just click-through rates, which has been a long-standing criticism of programmatic advertising. If this ships, it's the kind of change that affects billions of ad impressions daily without users ever noticing it directly.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.