Google Patents an AI That Fits Real Objects Into Any Art Style Without Losing Their Details
Imagine taking a photo of your coffee mug and asking an AI to place it inside a watercolor painting — without the mug losing its shape, logo, or handle. That's the specific problem Google's latest patent is solving.
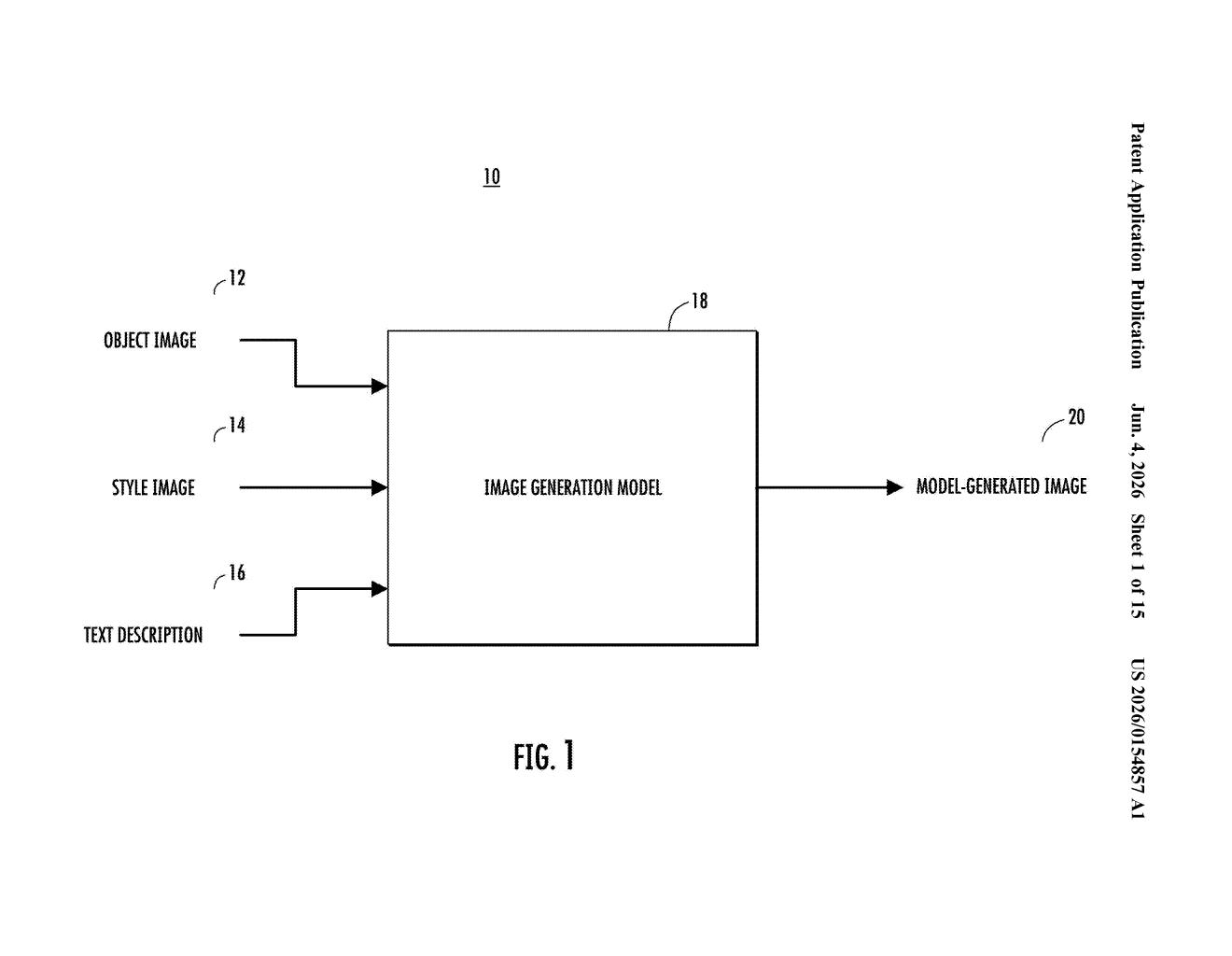
What Google's style-aligned image generator actually does
You give the system three things: a photo of an object you care about, a reference image with an art style you like, and a text description of the scene you want. The AI's job is to combine all three — keeping your object recognizable, wrapping it in the style of the reference image, and building out a scene that matches your text prompt.
The tricky part is making sure the object doesn't get "lost" inside the style. A painting-style filter applied to a whole image tends to warp or dissolve fine details. Google's approach traces the object's silhouette first (the "mask"), uses that to lock in the object's features, then renders the scene around it in the target style.
The result is a generated image where your specific object sits naturally inside a stylized scene — rather than looking pasted-on or smeared by the style filter. Think product mockups, personalized greeting cards, or creative ads where a real item needs to feel native to an illustrated world.
How the mask embedding and diffusion steps combine
The system takes three inputs — an object image, a style image, and a text description — and feeds them through a diffusion-based image generation model (the same category of AI behind Stable Diffusion and Imagen).
The model runs two parallel tracks:
- Object track: It generates a silhouette mask from the object photo, then encodes the object's visual features (shape, texture, color detail) into an object embedding — a compact numerical fingerprint of what the object looks like.
- Scene track: It uses the style image and text prompt to generate a background scene that matches the requested setting and carries the visual style of the reference image.
The clever bit is something called reduced attention sharing during diffusion. Normally, style-transfer methods let the style image's influence bleed across the entire output — including the object — which can distort it. By dialing back how much the style image's "attention" (the model's mechanism for deciding which parts of the input to prioritize) is shared with the object region, the system preserves the object's identity while still stylizing the surrounding scene.
Finally, the model composites the object embedding into the stylized scene, producing a single image where the object looks like it belongs in that illustrated or painted world rather than being digitally inserted.
What this means for product photography and creative tools
For anyone doing product photography, e-commerce, or marketing creative, this is a meaningful workflow change. Right now, placing a real product into a stylized scene requires a designer, a photo shoot, or tedious manual masking in Photoshop. A system like this could automate the whole pipeline — give it a product shot and a mood board, get back a batch of on-brand lifestyle images.
Beyond commerce, this sits squarely in the middle of Google's push to make Imagen and Gemini-era tools more controllable for creators. The ability to anchor a generated image to a specific real object — not just a generic "chair" or "mug" — is one of the harder unsolved problems in generative AI, and this patent describes a concrete architectural approach to it.
This is a genuinely useful patent tackling one of the real friction points in AI image generation: keeping a specific object intact while stylizing everything around it. The mask-plus-reduced-attention approach is technically coherent and solves a problem that casual users of Midjourney or Firefly run into constantly. It's not a flashy moonshot — it's the kind of plumbing that would make Google's image tools noticeably more useful for product and creative workflows.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.