Google's New Patent Teaches Its Image AI to Read Pictures Like Words
Text-based AI understands words because everything gets broken down into discrete tokens — bite-sized numeric codes. Google is now filing a patent to do the exact same thing with images, letting the same AI engines that power chatbots also read and generate pictures.
How Google turns pictures into AI-readable number codes
Think about how your autocomplete keyboard works: it doesn't see your message as raw letters — it converts everything into numbered chunks it can predict and manipulate. Google's patent describes doing something very similar with images.
Instead of feeding a photo directly into an AI, the system first compresses it into a grid of small numbered codes called visual tokens. Each region of the image gets its own code — a shorthand the AI can work with just like it works with words in a sentence.
Once an image is expressed in that format, an AI language model can treat it almost like text — analyzing it, editing it, or generating a new image from scratch by predicting which codes should appear where. The goal is one unified AI brain that handles both words and pictures, without needing totally separate systems for each.
How the encoder maps image features to integer token grids
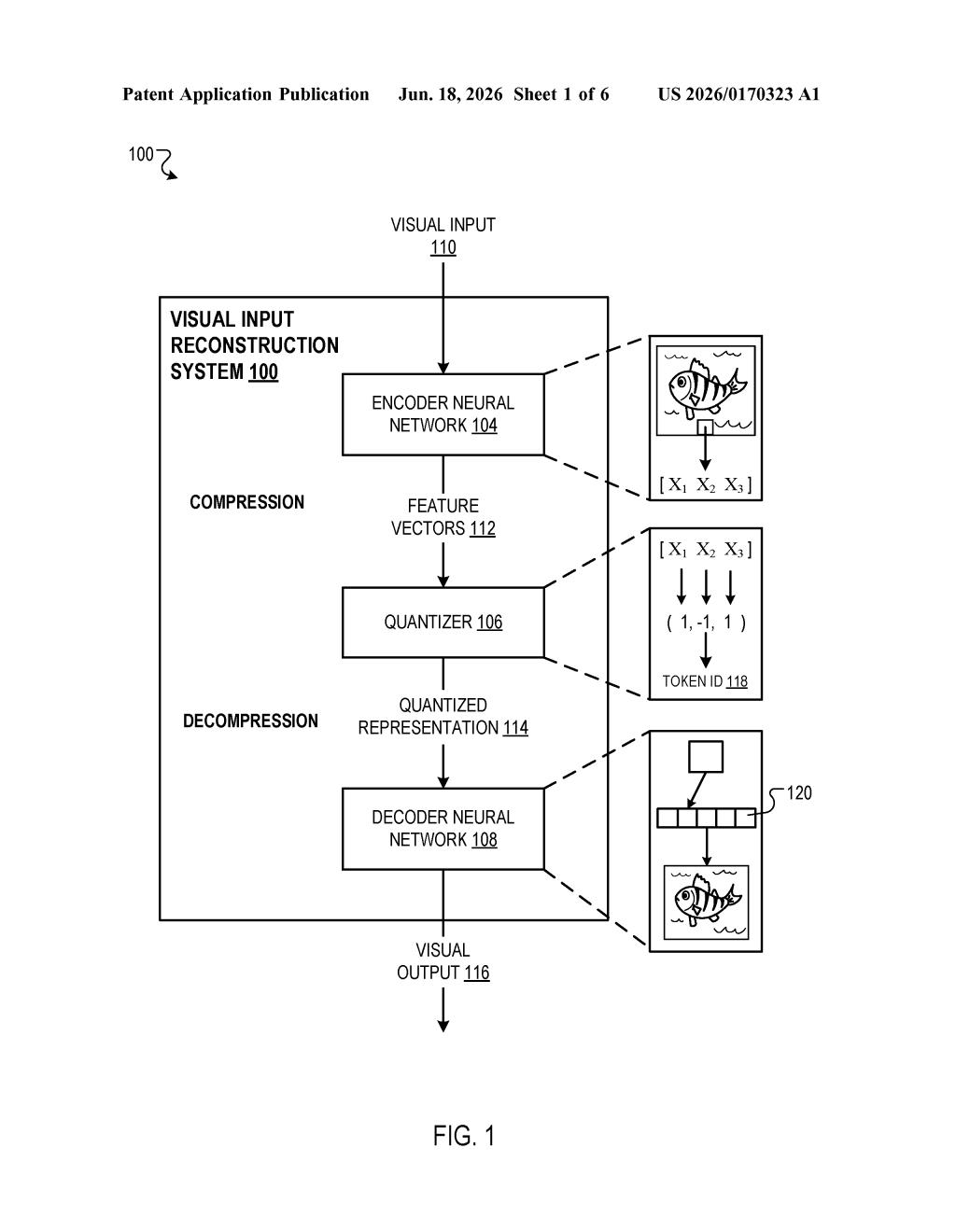
The patent describes a two-step pipeline for converting images into discrete numeric representations and back again.
Encoding: An image is fed into an encoder neural network — a model trained to extract meaningful patterns. Rather than outputting a continuous blob of numbers (the usual approach), this encoder produces a set of feature vectors (think of each one as a compact fingerprint for a small region of the image). Each vector's individual dimensions — its component measurements — are then each snapped to the nearest whole number from a fixed set. That snapping process is called quantization.
Tokenization: Those integer values are combined to identify a single visual token from a pre-built vocabulary — just like a dictionary, but for image patches instead of words. The result is a sequence of tokens that represents the entire image in a form a language model can natively process.
Decoding: When generating a new image, a model produces a sequence of such tokens, and a decoder neural network translates them back into actual pixels. The patent also describes conditioning this generation step on an input — meaning you could prompt the system with text or another image and get a coherent visual output.
The key technical claim is that quantizing each dimension independently (rather than treating the whole vector as one code) gives the system a much larger effective vocabulary without an explosion in memory or lookup-table size.
What this means for AI that generates and understands images
For years, image AI and text AI have been separate beasts — one for writing, one for pictures, with awkward bridges between them. This patent describes infrastructure to collapse that gap, letting a single language model architecture handle image understanding and generation natively using the same token-prediction machinery it already uses for text.
If this approach works at scale, it would make building products like image editors, visual search tools, or multimodal assistants significantly simpler, since you wouldn't need to stitch together fundamentally different model types. Google already ships multimodal products like Gemini, and this patent fits squarely into the research plumbing that makes those products possible.
This is foundational infrastructure work — not a flashy user-facing feature, but exactly the kind of patent that tends to show up quietly in production systems a year or two later. The specific contribution (per-dimension integer quantization for visual tokens) is a genuine engineering decision with real downstream consequences for model quality and efficiency. Worth tracking if you follow the multimodal AI space.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.