Microsoft Patents a Spatiotemporal Memory System That Makes Video Searchable in 3D
Microsoft is building what amounts to a spatial long-term memory for video — a system that can answer questions like "where was that red bag, and when did someone pick it up?" by indexing video not just by time, but by location in a 3D map.
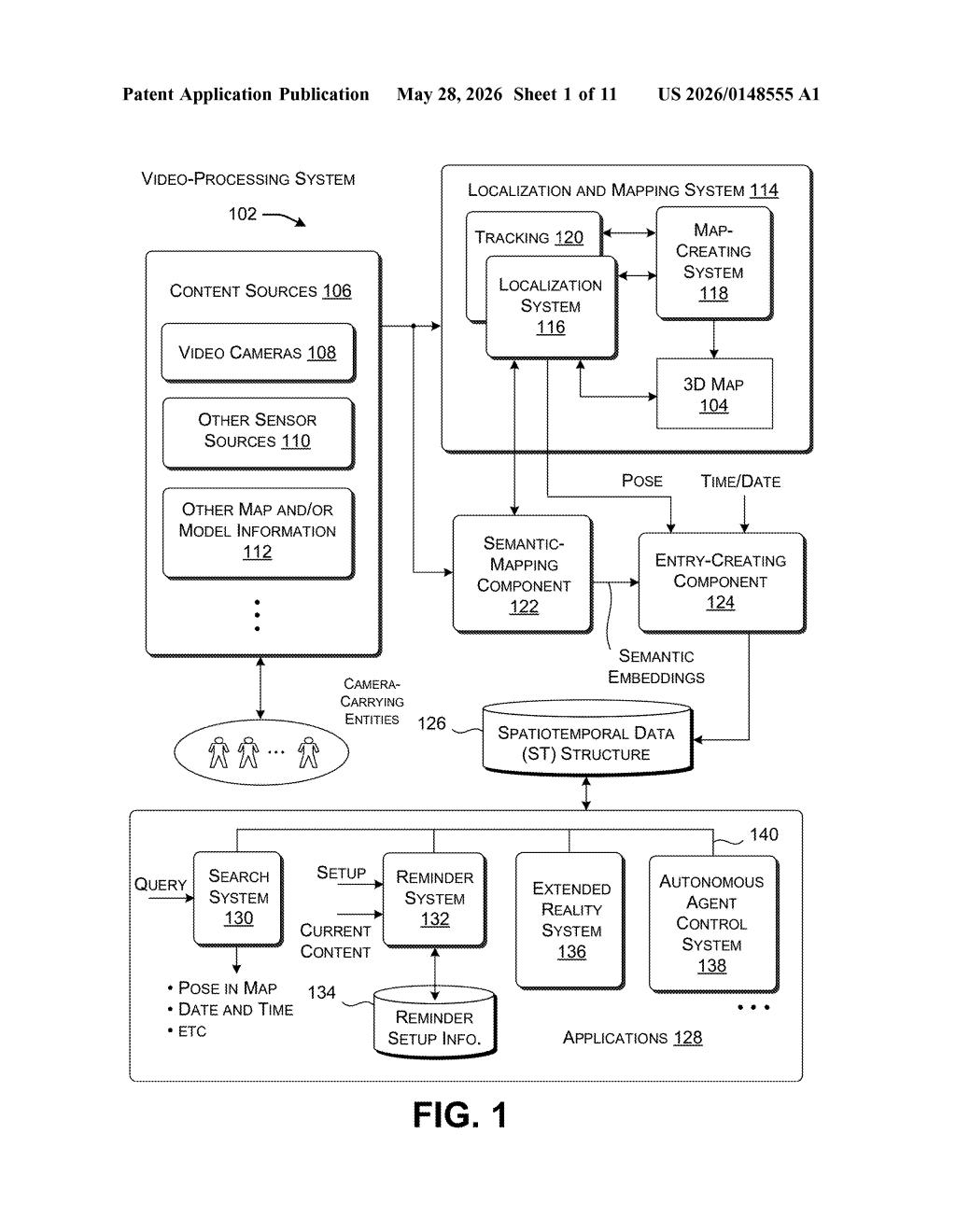
What Microsoft's spatial video recall system actually does
Imagine you're wearing a headset that records everything you see throughout your day. Hours later, you ask: "Where did I leave my keys?" or "When did the delivery person arrive?" Today, that means scrubbing through footage manually. Microsoft's patent describes a system that makes that kind of question answerable instantly.
The idea is to process video from one or more cameras and build a structured, searchable database that knows not just what happened in the footage, but where in the physical world it happened and when. Every object, action, and sound gets tagged with its real-world 3D position and a timestamp.
When you later ask a question — in plain text or some other format — the system converts your query into the same kind of mathematical representation used to index the video, finds the best match, and retrieves the relevant clip or location. Think of it as a Google search for your spatial memory.
How the embeddings, poses, and queries fit together
The system starts by decomposing incoming video into three distinct media-type parts: image information (individual frames), text or audio content (captions, speech, ambient sound), and video segment information (short multi-frame clips that capture motion or actions).
Each of those parts is then run through a neural network — specifically a multi-modal language model — to generate embeddings (dense numerical vectors that represent meaning). So a frame showing a coffee mug, a spoken phrase, and a clip of someone picking something up each get their own embedding in a compatible mathematical space.
In parallel, the system runs localization and mapping (think SLAM — Simultaneous Localization and Mapping, the same tech used in autonomous robots and AR headsets to build a 3D model of a space). This produces a pose — a precise position and orientation in 3D space — for the camera at every moment, plus estimated poses for objects and actions visible in each frame.
All of this gets bundled into a spatiotemporal data structure: a database where each entry holds multi-modal embeddings, a 3D position, and a timestamp. Queries are converted into the same embedding space, matched against entries, and the relevant video segment or location is returned.
What this means for AR headsets and video intelligence
This is clearly aimed at mixed reality and wearable computing — the kind of always-on camera systems in devices like the HoloLens or similar spatial computing hardware. If you're building an AI assistant that lives inside a headset, giving it a searchable, spatially-aware memory of everything it has seen is a foundational capability. Microsoft's patent covers exactly that infrastructure layer.
For you as a user, the practical upshot is a headset or workspace camera system that can answer natural-language questions about past events, tied to specific places in the real world. That's a meaningful step beyond basic video search — it collapses the gap between "I remember seeing that somewhere" and actually finding it.
This is serious infrastructure work, not a flashy demo patent. The combination of multi-modal embeddings with 3D pose estimation in a unified queryable structure is exactly the kind of hard, unsexy problem that needs to be solved before spatial AI assistants become genuinely useful. The inventor list — including Marc Pollefeys, a leading authority on 3D computer vision — signals this isn't just a speculative filing.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.