Microsoft Patents a Way to Teach AI by Focusing on Its Worst Mistakes
When you train an AI model, not all examples are equally useful — but most training methods treat them as if they are. Microsoft's new patent tries to fix that by making the model pay closer attention to the responses that are unusually good or unusually bad.
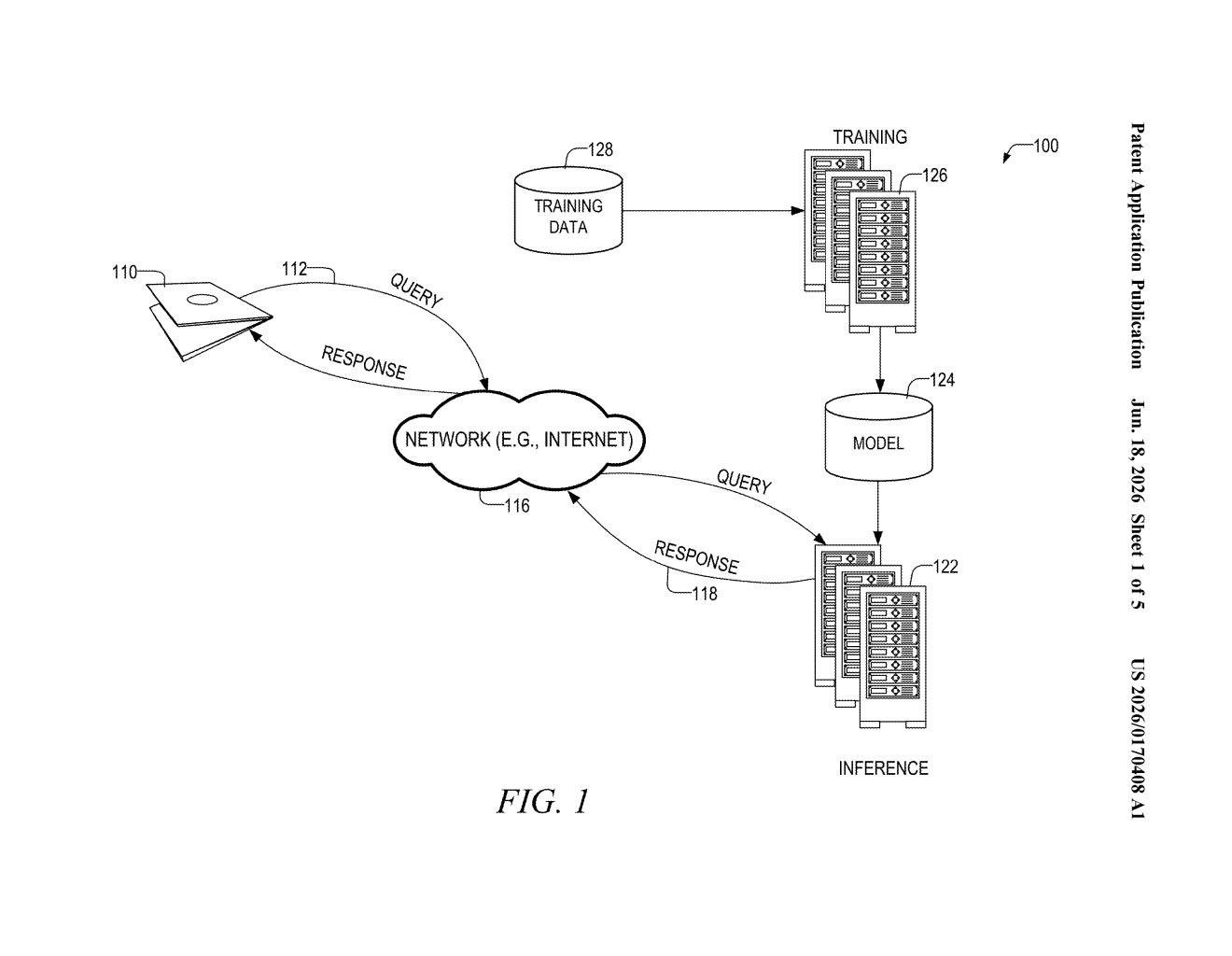
What Microsoft's SWEPO training method actually does
Imagine a student studying for an exam by reviewing every practice question the same way — spending equal time on the ones they barely missed and the ones they got spectacularly wrong. That's not a great strategy. Microsoft's patent applies the same logic to AI training.
When companies train large AI models, they typically show the model pairs of responses and tell it which one is better. SWEPO — the method described in this patent — goes further by asking: how much better? A response that's only slightly above average gets less emphasis; one that's dramatically better or worse gets weighted more heavily.
The result is that the AI spends its training budget on the examples that are most likely to actually teach it something, rather than grinding through hundreds of nearly identical, middling responses. It's a more efficient and, in theory, more accurate way to shape how an AI behaves.
How SWEPO weights responses during model training
The patent describes a training technique called Simultaneous Weighted Preference Optimization (SWEPO), designed to reduce what it calls "alignment biases" — situations where an AI model learns suboptimal behavior because its training signal wasn't sharp enough.
Here's how the process works at a high level:
- For each query in the training dataset, the system collects multiple AI-generated responses, each scored by a reward model (a separate AI that judges response quality).
- It calculates the average reward score across all responses for that query, then measures how far each individual response deviates from that average.
- Responses are split into a positive set (better than average) and a negative set (worse than average or equal to the mean).
- Each response is assigned a weight proportional to how far it sits from the average — outliers in either direction get the highest weights.
Those weights feed into a contrastive loss function (a mathematical signal that tells the model how wrong it currently is, calibrated to penalize the most egregious errors the most). The model's parameters are then updated to minimize that loss.
The method can run on a single machine or across distributed computing infrastructure, which matters for practical deployment at scale.
What this means for AI reliability and safety work
AI alignment — getting models to behave the way their developers intend — is one of the core unsolved problems in the industry. Most current methods treat all training examples with equal weight, which means the model wastes capacity on uninformative, average-quality examples. SWEPO addresses that directly by concentrating the training signal where it does the most work.
For you as an end user, better-aligned models mean AI assistants that are more consistent, less likely to produce confidently wrong answers, and better at following nuanced instructions. This kind of infrastructure-level training improvement is unglamorous but it's precisely the type of work that separates reliably useful AI from unpredictably flaky AI.
This is genuinely solid foundational work — not a flashy consumer feature, but the kind of training-methodology improvement that quietly raises the floor on model quality across everything Microsoft builds on top of it. The core idea (weight your training examples by how informative they are, not just by which direction they point) is intuitive and well-motivated. Worth watching if you follow AI safety and alignment research.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.