Xilinx Patents a Parallel Compression System That Switches Between Speed and File-Size Modes
Compressing data faster usually means compressing it worse. Xilinx is filing a patent for a chip-level system that runs multiple compression engines side by side — and picks the right strategy automatically.
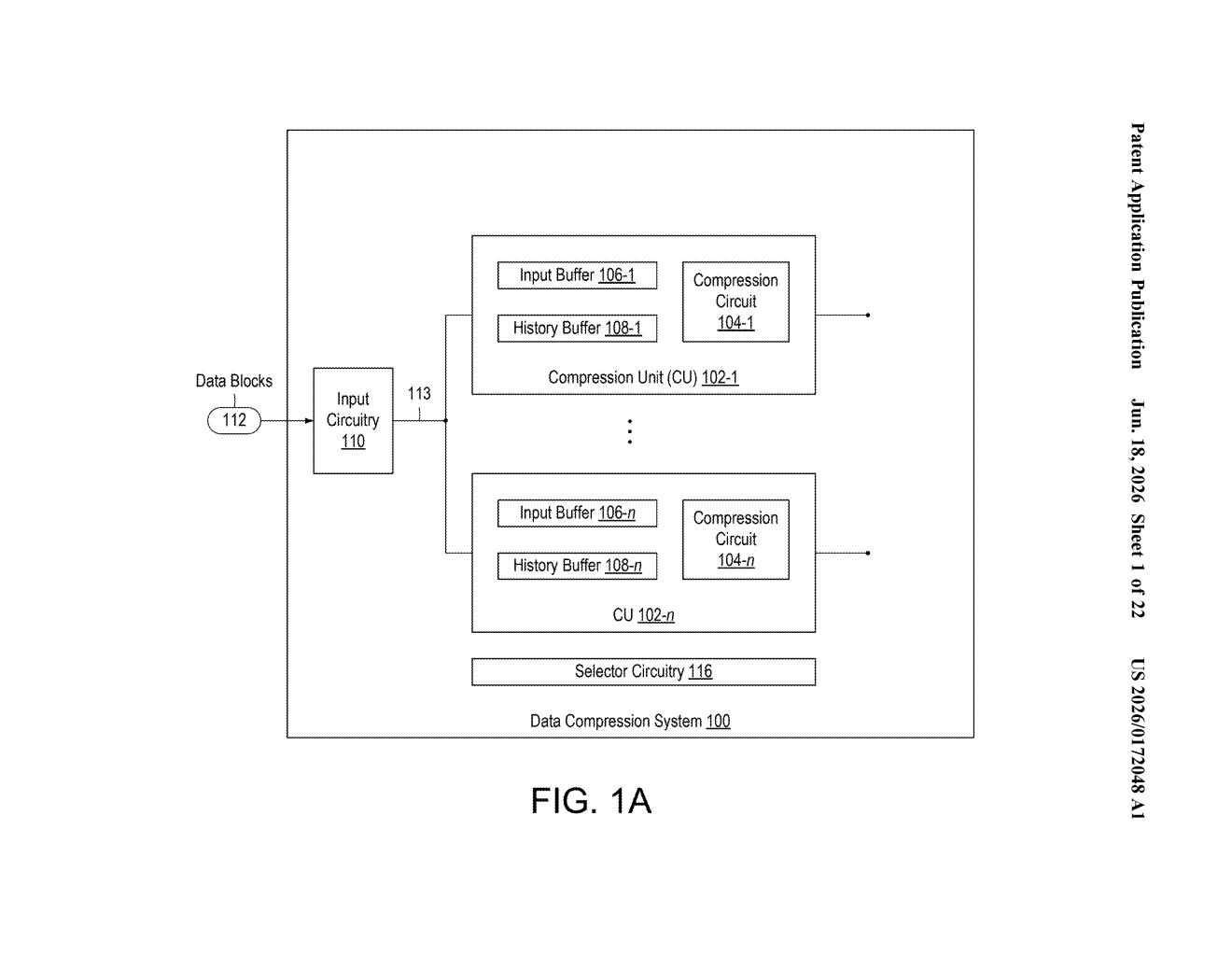
What Xilinx's parallel compression chip design actually does
Imagine you're packing boxes for a move. You can stuff things in quickly (fast but bulky) or fold and organize carefully (slower but fits more in the truck). Most compression software has to pick one approach and stick with it.
What Xilinx is describing here is a system that runs several compression engines in parallel — each handling a different chunk of data at the same time. Each engine looks at the data it's been handed and spots patterns: sequences it's seen before, which it can just reference by location instead of repeating in full. That's the basic trick behind most file compression.
The interesting part is that this system can switch modes depending on what's needed. If you need data out the door fast, it uses a high-throughput mode. If squeezing every byte matters more, it shifts to a high-compression mode. A third setting picks automatically based on available resources and how well the compression is actually working.
How the compression units split, match, and encode data blocks
The patent describes a hardware compression system made up of multiple compression units (CUs) — essentially independent compression engines that can operate simultaneously on different chunks of the same data.
Each CU has three parts:
- A compression circuit — the logic that does the actual encoding work
- An input buffer — a small memory holding the data currently being compressed
- A history buffer — a memory of data that was seen earlier in the stream
The system works by breaking a data block into sub-blocks and distributing them across the CUs. Each circuit then scans its sub-block for sequences that already appeared in the history buffer (this is called LZ-style matching, the basis of formats like ZIP and gzip). Instead of storing the repeated sequence again, it just records where in the history the match was found — a much shorter reference.
The patent also defines multiple compression modes: a high-throughput mode that prioritizes speed, a high-compression-ratio mode that prioritizes file size, and a dynamic mode that monitors results and resources in real time to choose between them automatically. Multiple data blocks can also be compressed in parallel, potentially using different modes simultaneously.
What this means for data centers and chip-level compression
This kind of hardware-accelerated, multi-mode compression is primarily relevant to data centers and FPGA-based infrastructure — the market where Xilinx (now part of AMD) operates. When you're pushing enormous volumes of data through storage or networking pipelines, doing compression in dedicated silicon instead of software can make a meaningful difference in throughput and power draw.
The automatic mode-switching angle is notable because it means the system doesn't need a human or separate controller to decide which strategy to use — it can read the situation and adapt. For cloud storage providers and anyone building custom chips for data pipelines, that kind of flexibility at the hardware level is genuinely useful, even if it won't show up anywhere a typical user would notice.
This is a solid infrastructure patent with no obvious consumer angle — it's squarely aimed at data center hardware and FPGA design. The parallel architecture and dynamic mode-switching are legitimate engineering improvements over fixed-mode compression pipelines, but the core LZ-matching concept is decades old. The novelty is in the modular, scalable packaging, not a new compression algorithm.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.