Qualcomm Patents Technology to Mix Two Creative Directions Into One AI Image
When you ask an AI image generator to follow both a text description and a reference photo at the same time, something usually gets shortchanged. Qualcomm's new patent targets exactly that tradeoff.
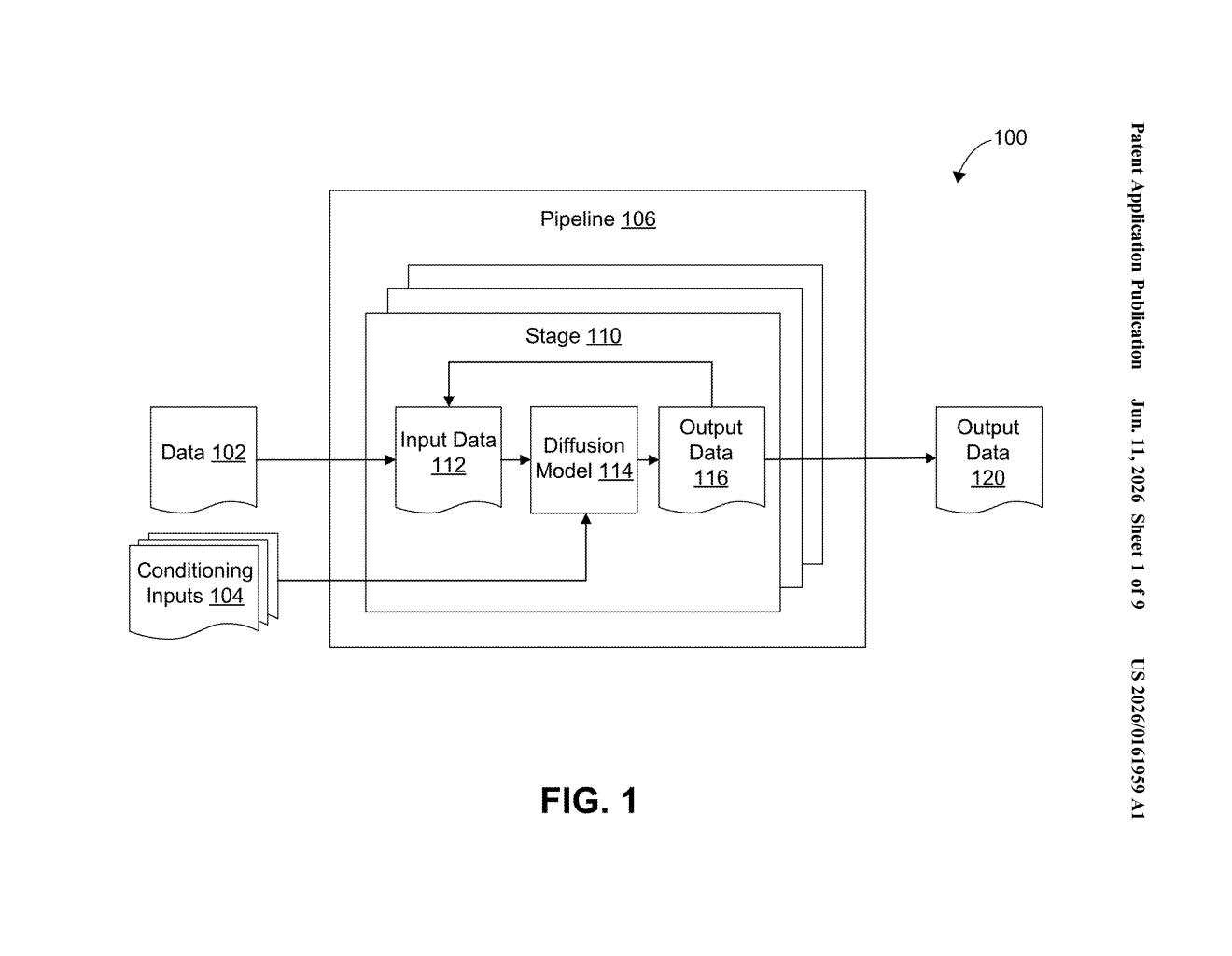
What Qualcomm's multi-prompt AI generation actually does
Imagine you're using an AI image tool and you want the result to match both a written description and a style reference photo — not just one or the other. Most generators today struggle to balance those two inputs gracefully; one tends to drown out the other.
Qualcomm's patent describes a system that runs the AI's generation process once for each type of instruction (say, the text prompt and the image reference), then carefully weighs each result before blending them together. Crucially, those weights can shift at different stages of the generation process, so the system might lean harder on one input early on and the other later.
The goal is a more faithful final output that genuinely honors all your inputs at once, rather than compromising between them. Qualcomm builds the chips — like Snapdragon — that power phones and PCs, so this kind of on-device AI generation is squarely in their wheelhouse.
How the diffusion model scales and merges each condition
The patent describes a multi-condition diffusion model — an AI image (or video, or audio) generator that can be steered by more than one type of prompt simultaneously.
At each step of the iterative generation process (diffusion models work by gradually refining a noisy image over many rounds), the system runs the model separately for each condition — for instance, once guided by a text prompt and once guided by a reference image. It then applies a scaling factor (essentially a tunable weight) to each of those separate outputs before adding them together to form the result for that round.
The key insight is that the scaling factors are tied both to the type of condition and to the current stage of the diffusion process. That means the system can dynamically rebalance how much each input influences the output as generation progresses — not just a fixed blend ratio.
- Run model with condition A → get output A
- Run model with condition B → get output B
- Multiply each by a stage-aware scaling factor
- Add the scaled results together to produce the next generation step
This is related to a known technique called classifier-free guidance (a method where the model is run with and without a guiding prompt to steer output quality), but extended to handle multiple, independently weighted conditions.
What this means for on-device AI generation on Snapdragon
For end users, this is about AI generators that actually do what you tell them when you give them more than one instruction. Today, mixing a style reference with a text prompt often produces muddy compromises. A system that tunes the influence of each input per generation step could yield noticeably more accurate results.
For Qualcomm specifically, the strategic angle is on-device AI inference. Running diffusion models locally on a Snapdragon chip — in a phone or a Copilot+ PC — requires squeezing every bit of quality out of limited compute. A more precise blending mechanism means better output without needing a larger, more power-hungry model. That matters a lot when your chip is competing against cloud-based generators that have essentially unlimited server resources.
This is a real and useful improvement to how diffusion models handle multiple simultaneous inputs, but it's an incremental engineering refinement rather than a conceptual leap. The interesting part is Qualcomm filing it — not a cloud AI lab — which signals how seriously they're investing in making on-device generative AI competitive on Snapdragon silicon.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.