Nvidia Patents a 3D Digital Human Foundation Model Built From 2D Photos
Nvidia is working on a system that can take ordinary, uncontrolled 2D photos — the kind scraped from the internet — and use them to train a generative model capable of producing detailed, poseable 3D digital humans, complete with face and hand detail.
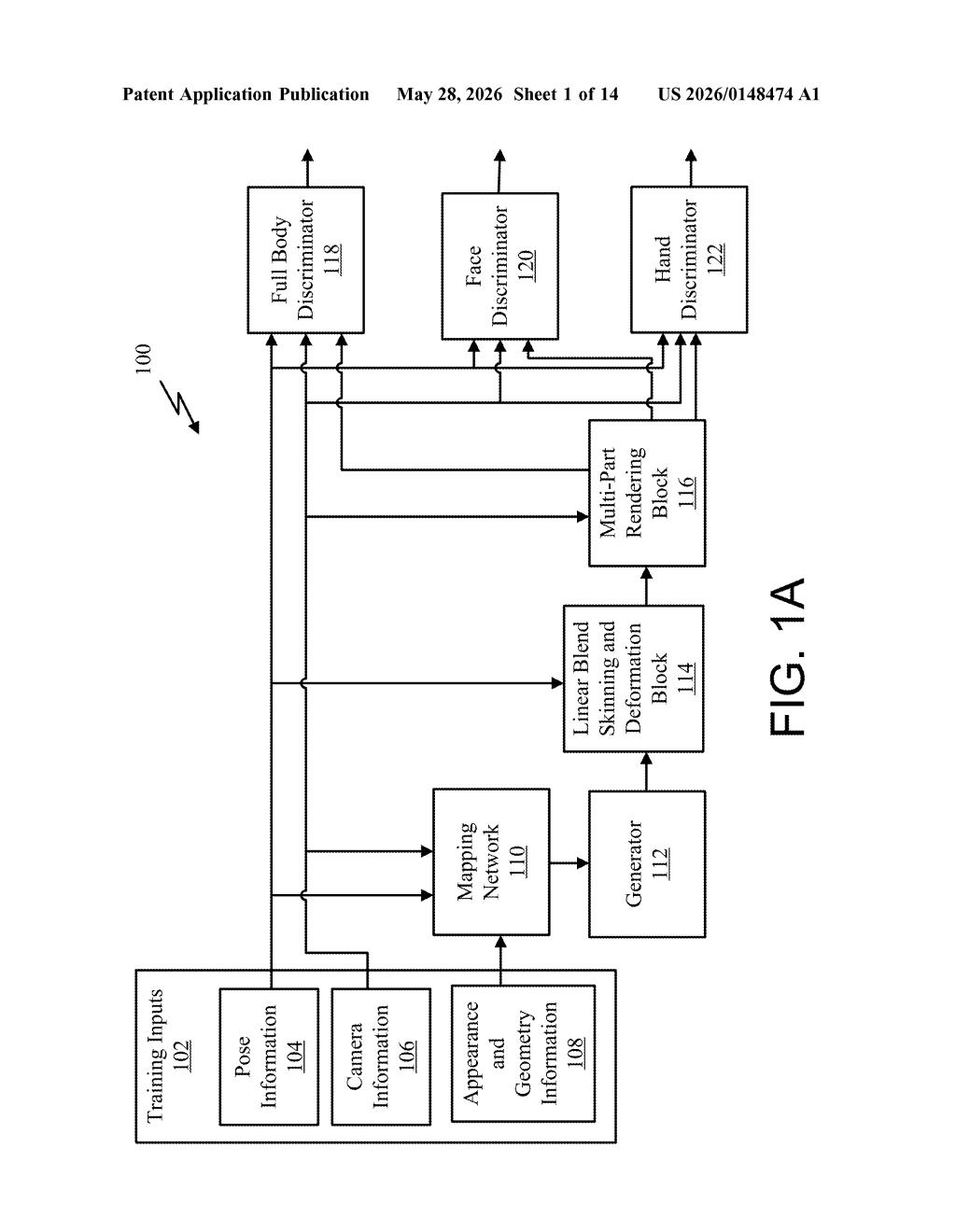
How Nvidia builds full-body 3D avatars from regular photos
Imagine you want to create a realistic 3D avatar of a person, but all you have are regular photos — selfies, stock images, social media posts. Normally, building a good 3D human model requires expensive camera rigs, controlled lighting, and precise scans. Nvidia's patent describes a way to skip all of that.
The system trains a generative model — the kind of AI that can create new images, not just recognize them — using those messy, "in the wild" 2D images. It learns the underlying 3D structure of how human bodies, faces, and hands look from any angle or pose, without ever having a 3D scan to start from.
The result is a digital human foundation model: an AI you can feed a pose or description into and get back a convincing, fully rendered 3D human. Think of it like a universal human template that can be dressed, posed, and animated on demand.
How Gaussian maps and skinning produce a full human render
The system is built around a Generative Adversarial Network (GAN) — an AI architecture where one network generates images and another critiques them, pushing quality up over time. The input is pose information: a mathematical description of how a human body is positioned in 3D space (think of it as a skeleton blueprint).
That pose data gets fed into a mapping network, which converts it into an intermediate latent code — a compact, abstract representation that captures the style and appearance details the generator needs. The generator then produces texel-aligned Gaussian maps. "Texels" are texture pixels mapped onto a 3D surface; "Gaussian maps" here refer to a technique called Gaussian splatting, where the 3D scene is represented as a cloud of fuzzy blobs rather than hard polygons — it's fast to render and very flexible.
Next, the system applies linear blend skinning and deformation — the same mathematical technique used in game engines to make a character's skin stretch and bend naturally when joints move. This step makes the Gaussian maps follow the body's actual motion.
Finally, a multi-part renderer composites everything together, paying special attention to the face and hands — the two body parts most critical for believable digital humans and notoriously hard to get right.
What this means for real-time avatars and digital humans
Digital humans are a bottleneck in games, film VFX, virtual production, telepresence, and avatar-driven AI assistants. The expensive part has always been capture — getting good enough source data. If Nvidia's approach works at scale, it could dramatically lower the cost of creating high-quality avatars by leaning on the billions of 2D photos that already exist online.
For Nvidia specifically, this fits squarely into its Omniverse and AI avatar platform ambitions. A foundation model for digital humans — one you can fine-tune, prompt, or pose — is a natural building block for real-time applications running on its GPUs, from game NPCs to enterprise virtual agents.
This is a technically dense patent tackling one of the hardest unsolved problems in computer graphics: generating believable, poseable 3D humans without expensive capture hardware. The combination of Gaussian splatting with GAN-based generation and articulated skinning is a genuinely interesting architecture choice, and Nvidia's team here includes some of the field's top researchers in digital humans. Whether this becomes a shipping product or stays a research paper is the open question, but the problem space is real and commercially important.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.