Nvidia Patents a Pipeline for Building 3D Digital Humans From Everyday 2D Photos
Training a 3D digital human model normally requires expensive, controlled capture setups — but Nvidia's new patent describes a way to do it from the messy, inconsistent photos you'd find anywhere on the internet.
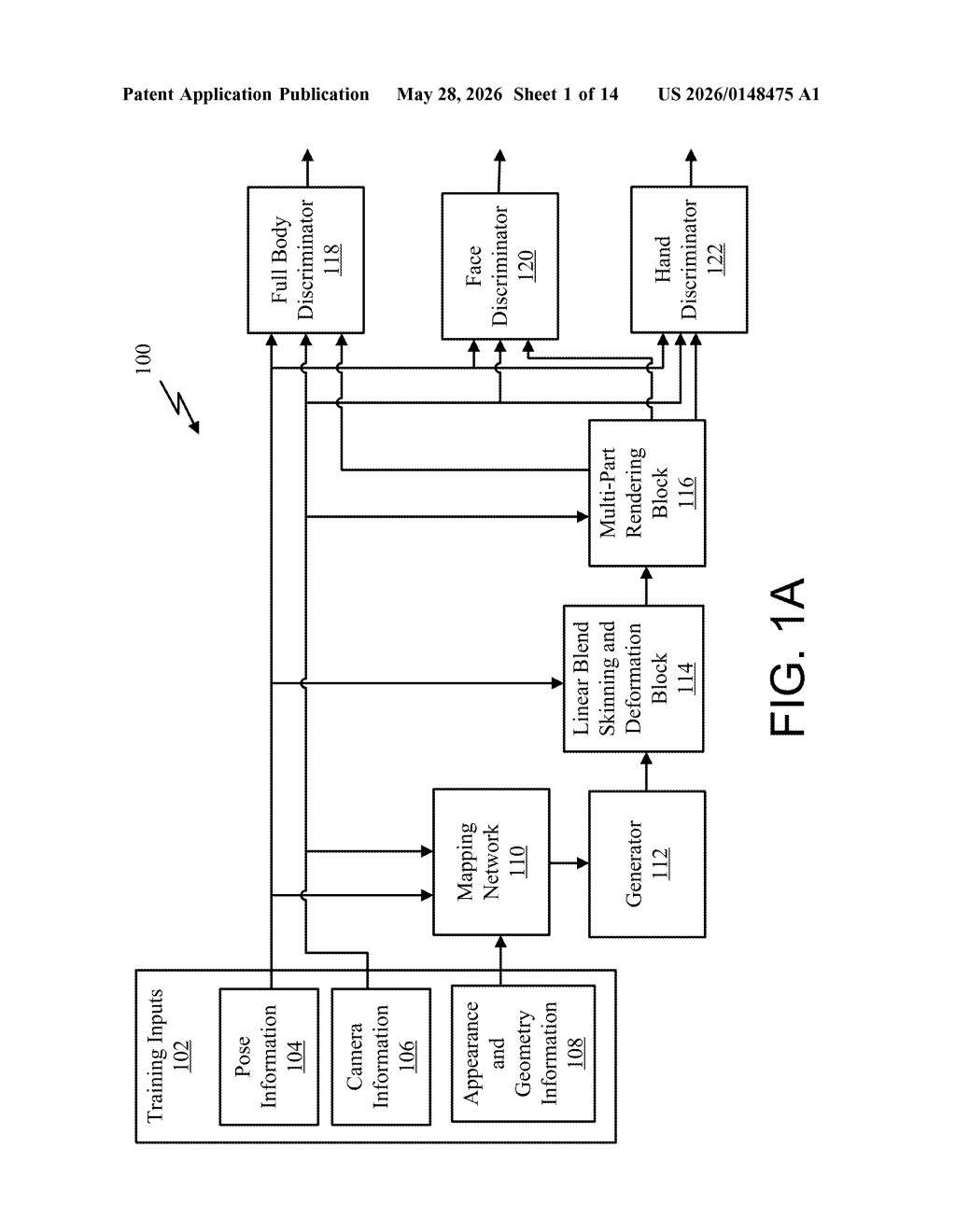
How Nvidia turns flat photos into 3D human models
Imagine trying to teach a computer to build a realistic 3D model of a person using nothing but regular photos taken from phones, security cameras, or social media. The problem is those photos are all shot from different angles, in different lighting, with no consistent reference point — so the computer has no easy way to figure out where someone's arm actually is in 3D space just by looking at a flat image.
Nvidia's patent describes a system that tackles exactly this. It takes a 2D photo, pulls out familiar body landmarks (like elbows, knees, and shoulders), and then uses a separate tool to estimate where those body parts sit in full 3D space. To check its work, it projects that 3D guess back down into 2D and compares it against the original landmarks — tweaking the 3D estimate until the two match up.
Once the system has clean, verified labels for real photos, it also generates synthetic (computer-made) images of humans to fill in the gaps — like rare poses or body types that don't appear often in real-world photos. The combined dataset then trains a foundation model that can understand and reconstruct the human body in 3D from images it's never seen before.
How the 2D-to-3D pose alignment pipeline works
The patent describes a multi-stage pipeline for building and curating a training dataset, then using that dataset to train a 3D digital human foundation model — a general-purpose AI that can reconstruct human bodies in 3D from 2D input images.
The core data-cleaning loop works like this:
- 2D landmark extraction: A standard pose-detection algorithm identifies key body points (joints, facial features) in a flat image.
- 3D pose estimation: A separate model guesses the full 3D configuration of the body — imagine lifting the skeleton off the page into a depth-aware coordinate space.
- Projection and comparison: The 3D estimate is mathematically projected back onto the 2D image plane using known camera parameters. If the projected 2D result doesn't match the originally detected landmarks, the 3D pose gets fine-tuned until it does.
- Label generation: Once aligned, both the 2D landmarks and the corrected 3D poses are stored as labels attached to that image.
Beyond cleaning real images, the system augments the dataset with synthetic humans — rendered using techniques like Linear Blend Skinning (a method for deforming a 3D mesh realistically as a virtual body moves) and multi-part rendering. This plugs holes in the real-world data where certain poses, body shapes, or lighting conditions are underrepresented.
The final trained model is described as a foundation model — meaning it's designed to be a general base that can be fine-tuned for downstream tasks rather than solving one narrow problem.
What this means for digital avatars and AI training data
Building high-quality 3D human models has traditionally required motion-capture studios with marker suits and controlled cameras. If Nvidia's approach works at scale, it shifts the data-gathering problem from expensive controlled capture to curating internet-scale 2D images — which is a much cheaper and more scalable input source. That's a meaningful infrastructure advantage for anyone building avatar systems, gaming engines, robotics, or AR/VR applications.
For Nvidia specifically, this feeds directly into its Omniverse and digital human platforms, where realistic, generalized 3D human models are a core building block. A robust foundation model here would let developers skip the hard data-collection step and fine-tune from Nvidia's pre-trained base — keeping more of that pipeline inside Nvidia's ecosystem.
This is a genuinely useful piece of ML infrastructure work. The pose-projection-and-reconciliation loop is a clever way to squeeze reliable 3D supervision out of noisy 2D data, and pairing it with synthetic augmentation addresses the long-tail distribution problem that plagues human pose datasets. It's not flashy, but this is exactly the kind of data-pipeline patent that ends up underpinning major product launches quietly.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.