Nvidia Patents AI System That Reconstructs 3D Scenes From Video at Any Point in Time
Nvidia has filed a patent for a system that takes ordinary multi-camera video and generates a full 3D volumetric snapshot of a scene at any timestamp — even moments that fall between recorded frames.
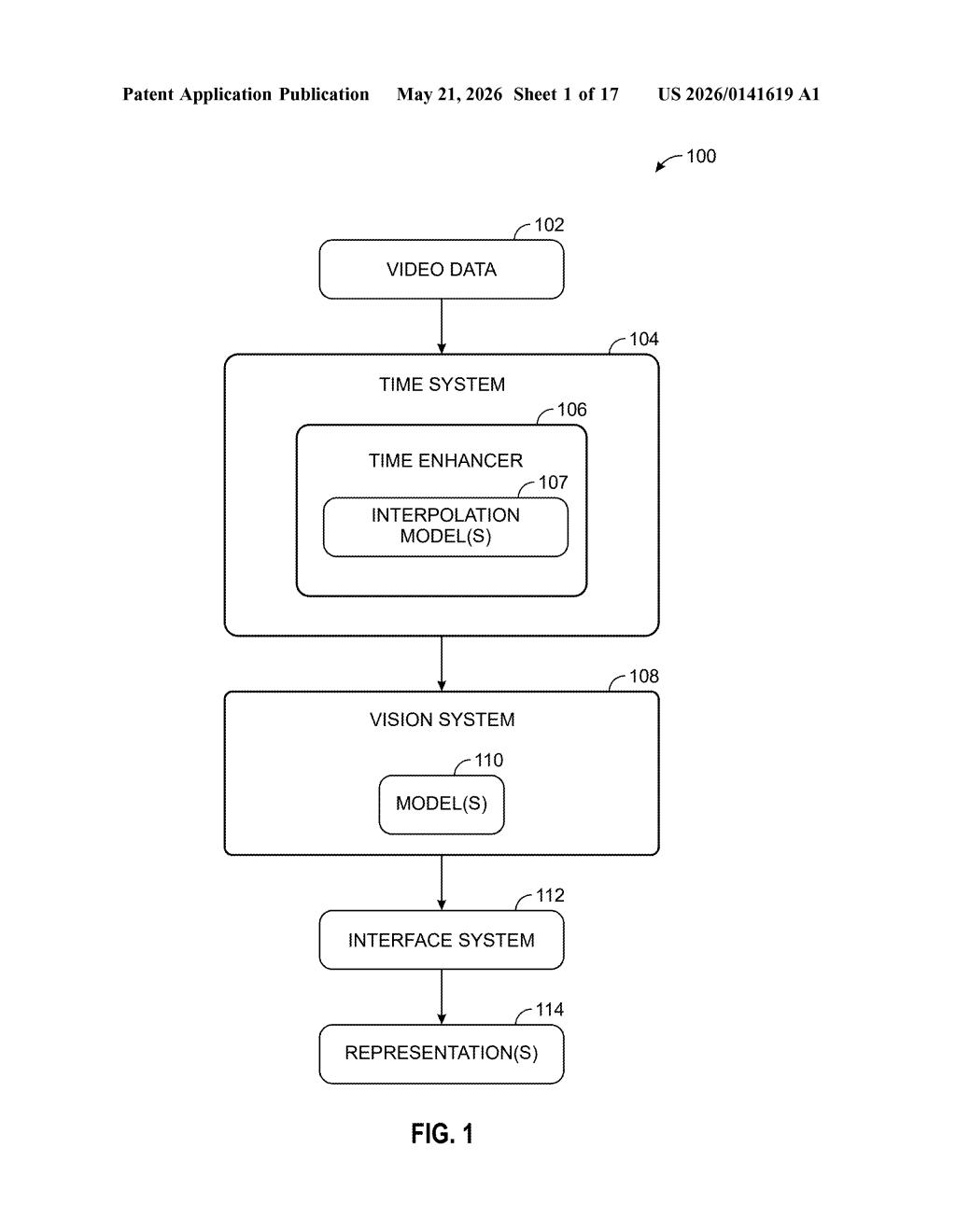
What Nvidia's video-to-3D scene builder actually does
Imagine you're watching a dashcam clip and you want to freeze a specific half-second and look at it from a completely different angle — not just pausing the video, but actually stepping around the scene in 3D. That's roughly what this patent describes.
Nvidia's system takes video captured from multiple cameras at multiple moments, feeds it into an AI model, and asks the model to produce a full volumetric — meaning depth-aware, 3D — representation of the scene at a specific point in time. That target time can be exactly when one of the frames was recorded, or it can be a moment between two frames that was never actually photographed.
The output isn't a flat image — it's a 3D structure you can render from any angle. Think of it like asking an AI to mentally reconstruct a room from a handful of snapshots, then let you walk around inside it.
How the vision model maps frames to a volumetric output
The system ingests a set of context frames — video frames paired with their camera poses (position and orientation in space) and timestamps. These are the raw ingredients.
A key step is selecting a reference timestamp: the moment in time the system should reconstruct. Crucially, this timestamp doesn't have to land on an actual recorded frame. It can sit between two frames, which means the system is doing something closer to temporal interpolation than simple frame lookup.
All three inputs — the video frames, their camera poses, and the target timestamp — are fed together into a vision model (a neural network trained to understand spatial and temporal relationships in scenes). The model outputs a volumetric representation, sometimes called a neural volume or implicit 3D scene representation, which encodes the scene's geometry and appearance in a format that can be rendered from arbitrary viewpoints.
The patent also mentions a time enhancer and interpolation model in its system diagram, suggesting a two-stage pipeline where temporal gaps between frames are explicitly bridged before the main 3D reconstruction step. The final volumetric output is then handed off to a rendering interface for multi-perspective visualization.
What this means for real-time simulation and robotics
For autonomous vehicles and robotics, this kind of system is enormously useful: training simulators need to generate photorealistic, viewpoint-flexible replays of real-world scenes, and being able to reconstruct any moment in time — not just recorded frames — makes those simulations far denser and more useful. Nvidia's Omniverse and DRIVE platforms are obvious candidates for this kind of capability.
For you as an end user, the downstream applications could include sports replay tools that let you orbit a moment in a game, film production tools for virtual production stages, or even AR/VR content pipelines that turn flat video into explorable 3D environments. The core challenge this patent addresses — temporal flexibility in 3D reconstruction — is one of the harder unsolved problems in neural rendering.
This is a technically serious patent from a team that includes researchers affiliated with MIT's CSAIL (Torralba Barriuso) and Nvidia's Toronto AI lab. The combination of temporal interpolation and volumetric scene generation addresses a real gap in neural rendering pipelines — most existing methods either reconstruct static scenes or struggle with between-frame moments. Whether this becomes a shipping product or lives as a research building block, it's the kind of foundational IP that matters for Nvidia's simulation ambitions.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.