Nvidia Patents a Location-Aware System for Reading Traffic Signs
A stop sign in Tokyo looks nothing like one in Texas. Nvidia's latest patent tackles that exact problem — teaching an AI to use geography as a hint when figuring out what a road sign means.
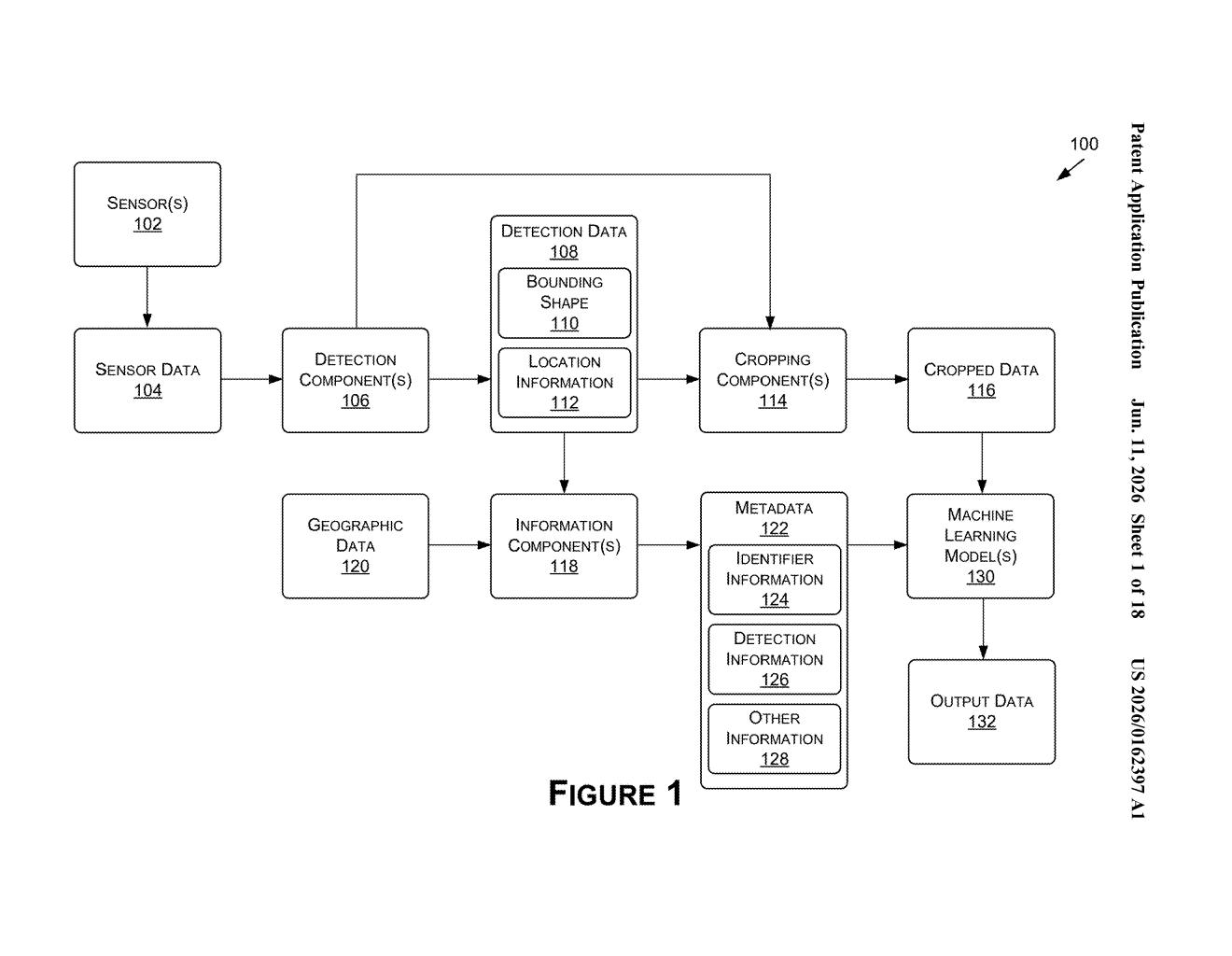
How Nvidia's traffic-sign AI uses location as a clue
Imagine you're driving through a country you've never visited and you spot a triangular red sign with an unfamiliar symbol. You'd probably use context — where you are — to guess what it means. Nvidia wants self-driving car systems to do the same thing.
This patent describes an AI that doesn't just look at a photo of a traffic sign in isolation. It also knows where the car is located — down to the geographic region — and feeds that location information into the same AI model that's analyzing the image. The idea is that a speed-limit sign in Germany follows different design rules than one in Japan or the United States, and knowing the country narrows down the possibilities dramatically.
The result is an object-classification system that's much harder to confuse. Instead of your car's brain making a pure visual guess, it's making an educated guess informed by real-world context — the same way you would.
How the model fuses cropped images with geographic metadata
The system works in a few coordinated steps:
- Crop the sign: When a camera detects a potential traffic sign in its field of view, the system draws a bounding box around it and cuts out just that portion of the image.
- Pull location metadata: The system then assembles metadata — structured data about the scene — including a geographic identifier (think country, region, or map zone) and details about the bounding box itself, like its dimensions and aspect ratio.
- Feed both into the AI: A machine learning model receives both the cropped image and the metadata as input simultaneously, rather than analyzing the image alone.
- Act on the result: Once the model returns a classification — "this is a 30 km/h speed limit sign" — the vehicle or machine uses that label to decide what to do next.
The key insight is that geographic context acts as a prior (a statistical head-start) for the classifier. Road-sign vocabularies are largely country- or region-specific, so knowing the location dramatically shrinks the list of signs the model needs to consider. Bounding-box shape data helps too — a tall narrow crop versus a wide flat one already tells the model something about sign shape before pixel analysis even begins.
What this means for autonomous vehicles crossing borders
For autonomous vehicles, misreading a traffic sign isn't an inconvenience — it's a safety issue. Current vision-only classifiers can struggle when signs are partially obscured, poorly lit, or simply unfamiliar because the car has crossed into a new region. Adding geographic metadata as a second input channel gives the model a meaningful cross-check that costs almost nothing computationally.
This also has practical implications for global deployment of self-driving systems. Rather than training separate models for every country's road-sign vocabulary, a single model informed by location data could handle a much wider range of environments. For Nvidia, whose DRIVE platform underpins many automakers' autonomous systems worldwide, that kind of geographic flexibility is a genuine engineering priority.
This is a tidy, practical idea rather than a flashy one. The insight — that geography is cheap metadata that dramatically constrains what a sign could possibly be — is the kind of engineering common sense that quietly improves real-world reliability. It's worth caring about precisely because it's unglamorous: this is the sort of detail that separates a demo that works on California highways from a system that actually works everywhere.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.