Nvidia Patents a Closed-Loop Fix for Self-Driving AI Training Drift
There's a well-known crack in how self-driving AI is trained: models learn from expert human drives, but when they hit the real world and make a small mistake, they've never been trained on what to do next. Nvidia's new patent directly targets that crack.
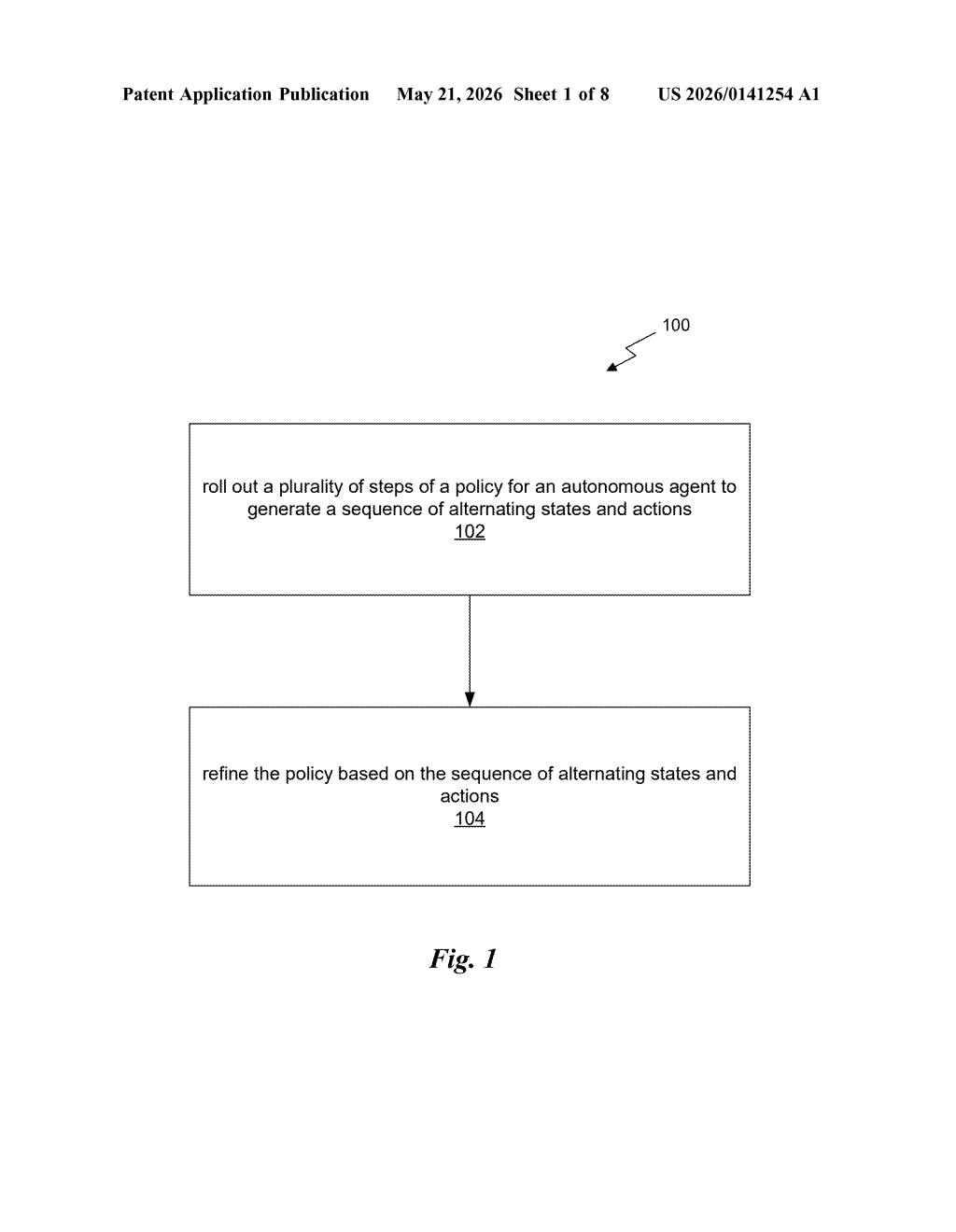
How Nvidia's self-driving AI unlearns bad habits
Imagine you're learning to cook by watching a chef make a perfect dish. You memorize every move — but the chef never shows you what to do if you accidentally burn the onions. The first time something goes wrong, you're on your own.
That's essentially the problem facing most self-driving AI today. These systems are trained by watching expert human drivers, but they're only shown perfect driving. The moment the car drifts slightly off the expected path, the AI is in unfamiliar territory — a problem researchers call covariate shift.
Nvidia's patent describes a training technique that closes this loop. Instead of just watching expert drives passively, the AI is made to actively practice driving, step by step, while being guided back toward what an expert would have done at each point. Over thousands of simulated iterations, the model learns not just ideal behavior, but how to recover when things aren't ideal — which is most of real driving.
How the rollout-and-align fine-tuning loop works
The patent describes a closed-loop supervised fine-tuning method for autonomous driving policies built on next-token-prediction (NTP) models — systems that treat a driving trajectory as a sequence of discrete tokens (think of it like predicting the next word in a sentence, but instead you're predicting the next movement of a vehicle).
The core problem: NTP-based driving models are trained in open-loop mode (they watch expert data without interacting with an environment), but they're deployed in closed-loop mode (their own actions change the world around them). That mismatch causes covariate shift — where small prediction errors compound over time because the model was never trained on the messy states those errors create.
The fix works like this:
- A pretrained driving policy is rolled out step-by-step through a simulated environment.
- At each step, the model generates multiple candidate actions.
- The system picks whichever candidate action would bring the car's next state closest to what an expert driver would have done — essentially providing corrective supervision at every step.
- The resulting sequence of states and actions is used to fine-tune the policy, teaching it to handle the kinds of off-nominal situations real driving produces.
The fine-tuned policy is then deployed to a real-world autonomous vehicle. The approach is compatible with existing tokenized trajectory models, meaning it can layer on top of architectures Nvidia (and others) are already investing in heavily.
What this means for the next generation of AV models
The covariate shift problem is one of the most discussed failure modes in imitation learning — it's not exotic research, it's a practical barrier to deploying reliable AVs. What makes this patent notable is that it addresses the problem without requiring reinforcement learning, which is computationally expensive and notoriously hard to tune for safety-critical systems. The approach stays within a supervised learning framework, making it easier to scale and audit.
For Nvidia's DRIVE platform and the ecosystem of AV developers building on its hardware and software stack, a robust closed-loop fine-tuning method could meaningfully improve how well tokenized driving models generalize from simulation to the real world. If this technique works as described, it's the kind of unglamorous-but-essential infrastructure that separates demo-quality autonomy from production-quality autonomy.
This is genuinely important work dressed in unglamorous clothes. Covariate shift has been a known Achilles' heel of imitation learning for years, and most production AV teams have quietly wrestled with it. Nvidia filing a patent on a practical, supervised-learning-compatible fix — rather than a RL-based one — suggests they're thinking about deployment realities, not just benchmark scores. Worth watching closely.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.