Microsoft's New Patent Trains Giant AI Models Across Datacenters Around the World
Training a giant AI model normally requires thousands of GPUs crammed into a single building. Microsoft's new patent describes a way to split that work across datacenters in completely different parts of the world — without everything grinding to a halt over a slow internet connection.
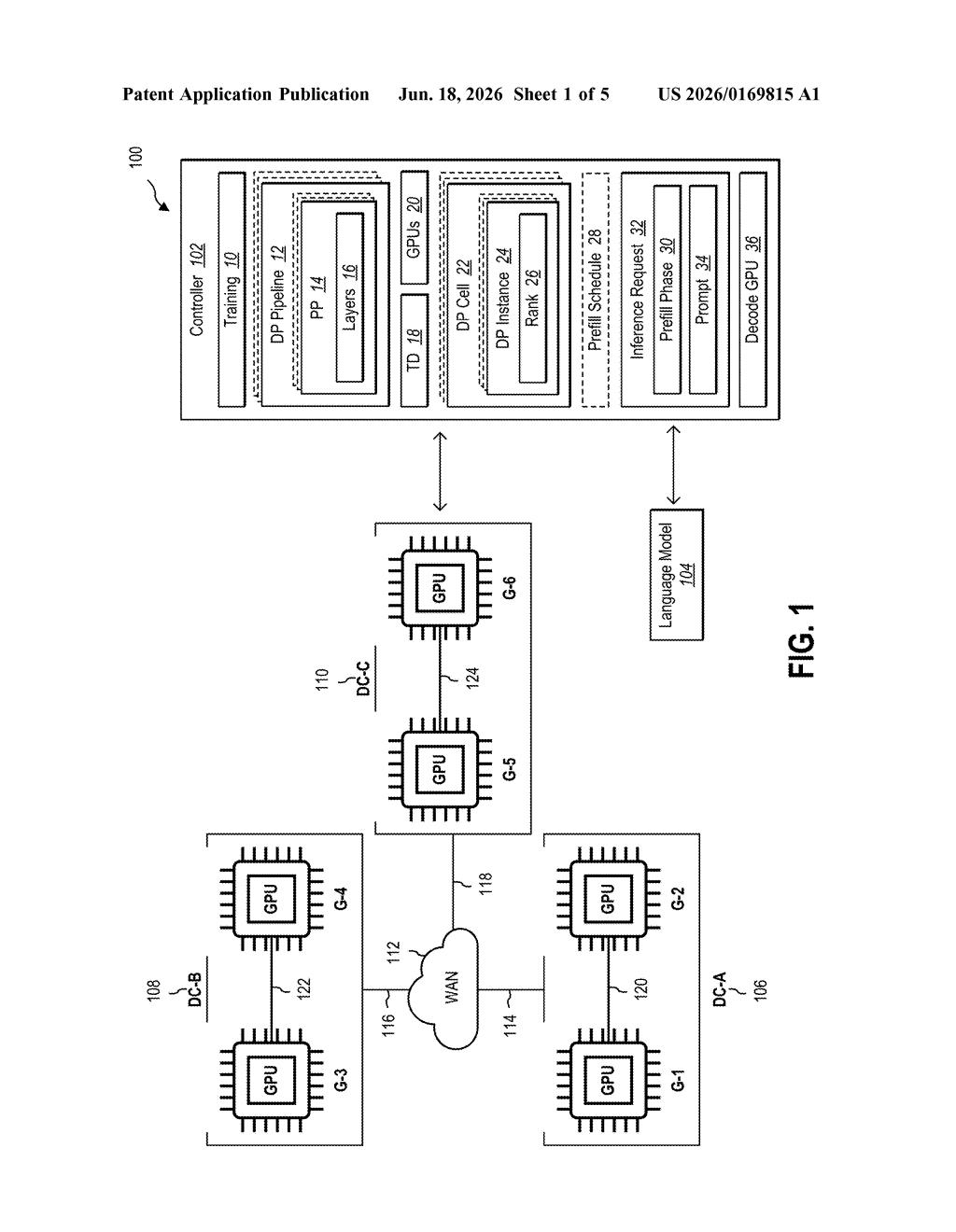
What Microsoft's geo-distributed AI training actually does
Imagine trying to write a novel with co-authors in New York, London, and Tokyo, all editing the same document in real time over a patchy Wi-Fi connection. That's roughly the problem Microsoft is solving here, but for AI training instead of writing.
Training a large language model — the kind that powers tools like Copilot — requires enormous computing resources. Normally, companies pack all those resources into one datacenter so the GPUs can talk to each other at top speed. Microsoft's patent describes a system that lets GPUs in different datacenters, connected by ordinary wide-area internet links, share that training workload without constantly waiting on each other.
The trick is a smart scheduling system that figures out how much data can travel between locations at any given moment, then lines up the work so only one chunk of training traffic crosses the long-distance connection at a time. Less congestion, less waiting, and AI training that can stretch across the globe.
How the scheduler manages bandwidth across distant datacenters
The patent describes a training framework that slices AI model training into three overlapping types of parallelism — and coordinates all three across datacenters connected by a wide area network (WAN), meaning the regular internet rather than the ultra-fast local cables inside a single building.
- Data parallelism — multiple copies of the model train on different batches of data simultaneously, then share what they learned.
- Pipeline parallelism — the model is cut into sequential layers, with different datacenters responsible for different stages, like an assembly line.
- Tensor parallelism — individual mathematical operations (tensors are the arrays of numbers the model computes over) are split across GPUs to run in parallel.
The key invention is the bandwidth-aware scheduler. The WAN link between datacenters is the bottleneck — far slower than in-building connections. The scheduler measures the available bandwidth in real time and queues the data parallel pipelines (the big cross-datacenter sync jobs) so only one runs at a time per datacenter. That prevents traffic jams while keeping the GPUs busy with local pipeline and tensor work in between.
What this means for the cost of building big AI models
Right now, building a frontier AI model essentially requires a single massive datacenter — or at least multiple datacenters close enough together to be connected by private high-speed fiber. That concentrates both the cost and the physical infrastructure in a handful of places. A system that works efficiently over standard long-distance internet links could let Microsoft pool GPU capacity that already exists in datacenters around the world, instead of building new mega-facilities from scratch.
For you, the practical upshot is that this kind of infrastructure work is what keeps AI model training costs from spiraling indefinitely — and cheaper training tends to translate, eventually, into more capable or more affordable AI products. It also signals that Microsoft is thinking seriously about how to scale AI infrastructure without always requiring brand-new construction.
This is unglamorous plumbing work, but it's genuinely important plumbing. The ability to train large models across geographically distributed GPUs over commodity internet links would be a real operational advantage — Microsoft has datacenters everywhere, and right now most of that hardware sits out of reach for training frontier models. Don't expect a press release, but do expect this kind of scheduling logic to quietly end up inside Azure's AI infrastructure.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.