Nvidia Patents a Progressive Difficulty Training Loop for Robot Control AI
Training a robot AI on tasks that are too hard from the start is a recipe for failure — so Nvidia's latest patent borrows a trick from human education: start easy, raise the bar only when the student is ready.
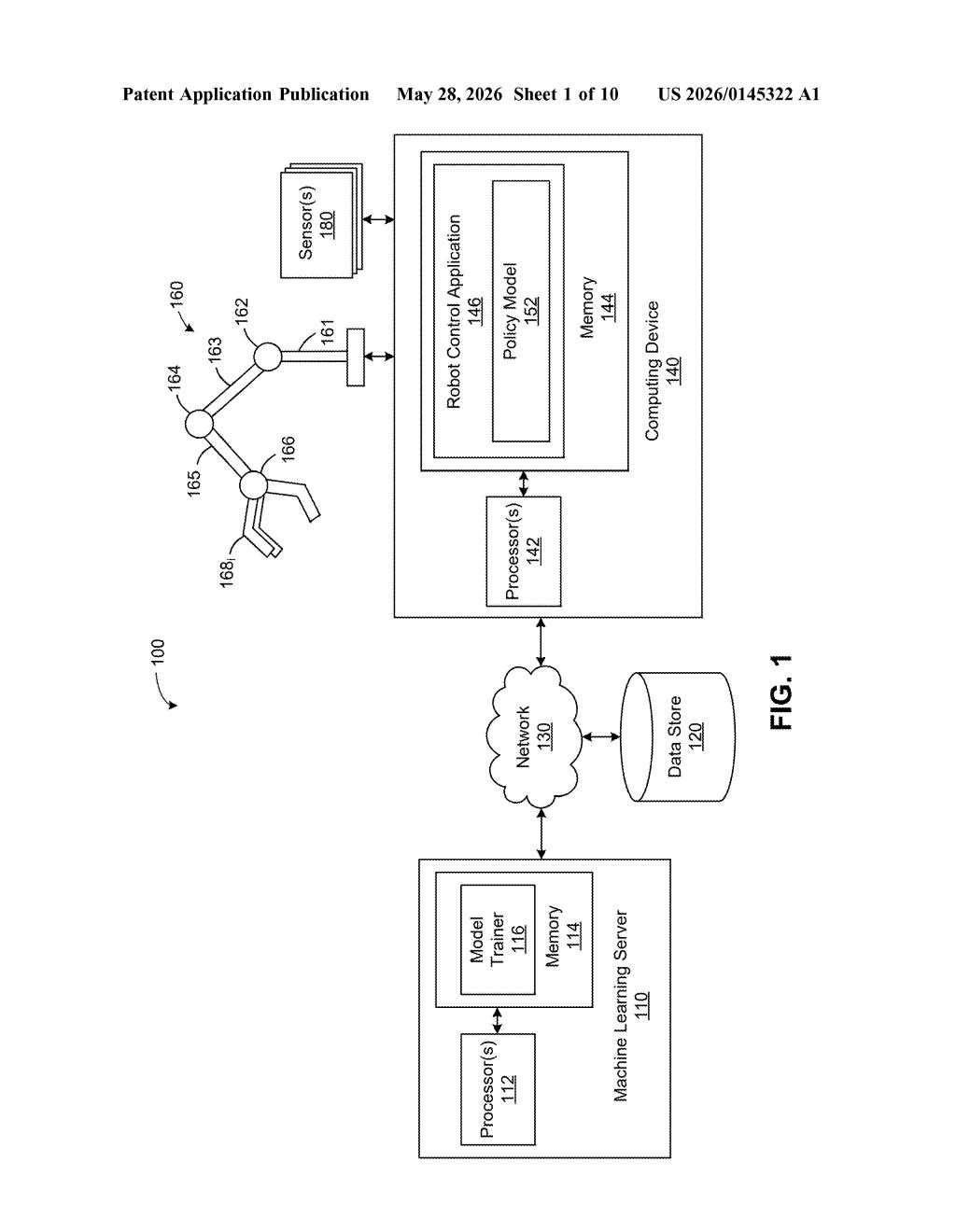
How Nvidia teaches robots to get harder tasks over time
Imagine learning to ride a bike by being dropped onto a mountain trail on day one. You'd fail constantly and never learn anything useful. The same problem plagues robot AI — if you throw a robotic arm at its hardest tasks immediately, it flails and the training stalls.
Nvidia's patent describes a system that works more like a patient coach. The robot AI trains on a range of difficulty levels for a given task. Once it hits a defined success rate, the system automatically slides the bottom of that difficulty window upward — retiring the easy stuff and keeping the ceiling the same. The robot is always challenged, never overwhelmed.
All of this happens inside a simulation first, so the AI can grind through thousands of attempts before it ever touches real hardware. The system tracks performance, adjusts the training curriculum on the fly, and keeps pushing until the robot is ready for the real world.
How the difficulty window shifts as the robot improves
The patent describes a curriculum reinforcement learning (RL) framework for robot control. In standard RL, an agent — here, a simulated robot — learns by trial and error, receiving rewards for good behavior and penalties for bad. The trick here is how the training tasks are structured over time.
The method defines tasks as having a range of difficulties, characterized by a lower bound and an upper bound. Training begins within a first range. The system then monitors the model's success rate at the task. Once that rate crosses a configurable threshold, the system automatically triggers a second training phase:
- The lower bound of difficulty rises — easy variants of the task are phased out.
- The upper bound stays the same — the hardest versions remain in scope.
- This effectively compresses the training distribution toward harder examples without discarding the ceiling.
All training occurs in simulation (a model of the robot and its environment), with outputs flowing from a policy model — the neural network that decides what the robot should do — through a model trainer that updates its parameters based on computed rewards and observations.
The architecture separates the machine learning server (where training happens) from a robot control application running on a separate computing device, with sensor inputs feeding back into the loop.
What this means for real-world robot deployment
Curriculum learning isn't a new idea in AI research, but codifying it as a concrete, automated training pipeline for physical robots is meaningful engineering work. The hardest part of robotic RL has always been getting training to generalize — a robot that aces easy grasps in simulation often collapses on anything slightly different in the real world. By systematically retiring easy examples as competence grows, this approach pushes the policy toward the harder edge of the distribution where real-world variance actually lives.
For you as a consumer, this is the kind of invisible infrastructure work that eventually shows up as robots that are more reliable in messy, unpredictable environments — think warehouse automation, surgical assistance, or home robotics. Nvidia's Isaac simulation platform is already a major player in robot training pipelines, and this patent fits squarely into that ecosystem.
This is solid, practical research rather than a moonshot. Automated curriculum scheduling addresses a real bottleneck in robot RL training, and the sliding-lower-bound approach is an elegant implementation detail. It's not conceptually shocking if you follow robotics research, but it's exactly the kind of methodological refinement that separates systems that work reliably in production from those that only work in demos.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.