Nvidia Patents a Dynamic Neural Network Workload Scheduler Across Multiple Processors
Running a giant neural network on a single chip is increasingly a bottleneck — Nvidia's new patent describes a system that watches performance metrics in real time and dynamically slices the network across two or more processors to keep things moving.
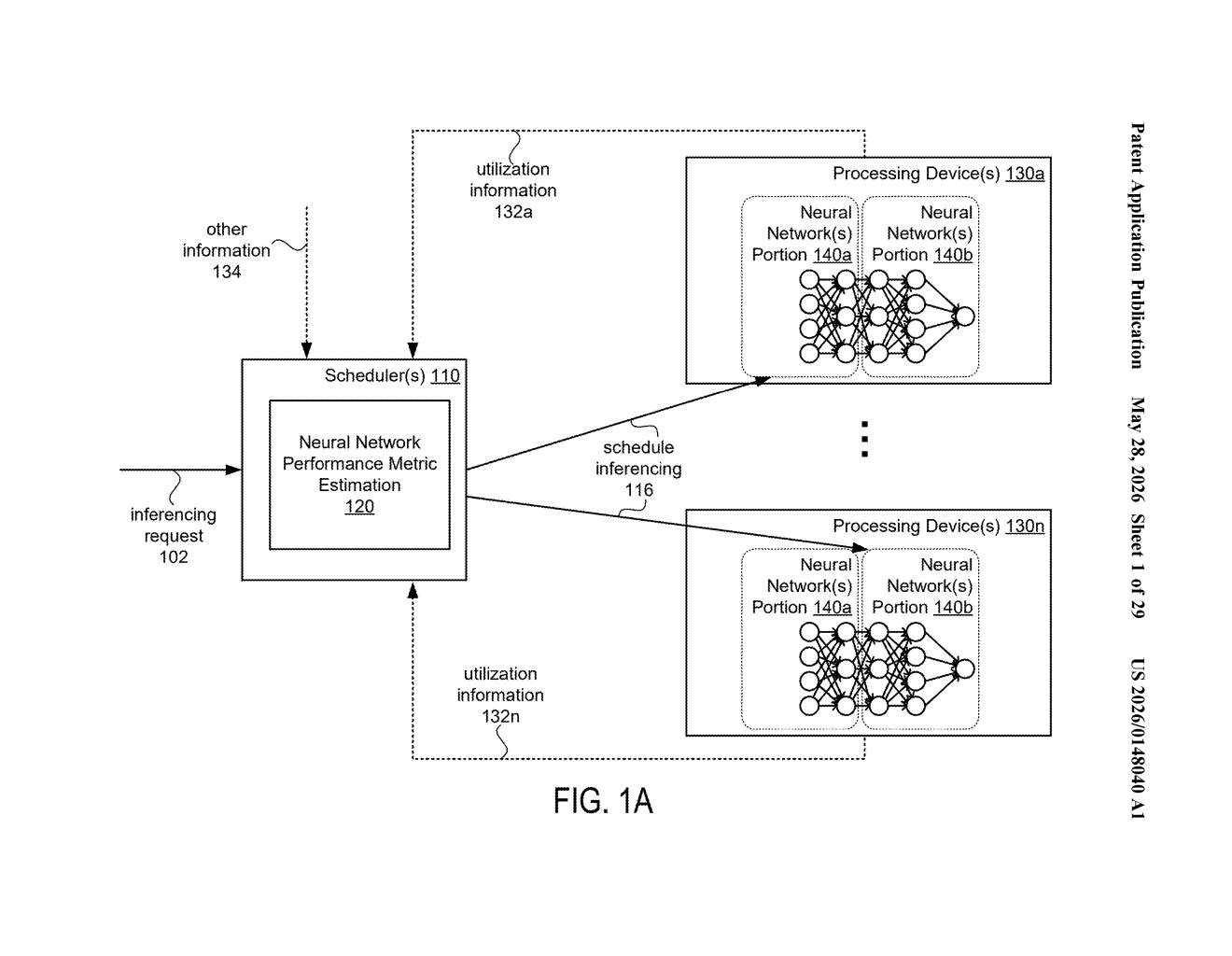
How Nvidia's neural network splitting actually works
Imagine trying to cook a massive Thanksgiving meal on a single burner. At some point, you'd naturally move pots to other burners to get everything done faster. Nvidia's new patent describes the same idea, but for AI models running on processors.
When a neural network — the kind that powers image recognition, language models, or robotics — gets too big or too slow for one chip, this system automatically figures out which portions of the network to offload to other processors. It doesn't do this blindly: it estimates performance metrics for each chunk before deciding where to run it.
The result is a more fluid, responsive way to spread AI computation across hardware — whether that's multiple GPUs, CPUs, or a mix. Instead of a fixed, pre-planned partition, the system adjusts dynamically as conditions change.
How the scheduler estimates and assigns network portions
The patent describes a processor — or coordinating circuit — that monitors estimated performance metrics for different portions of one or more neural networks. Based on those estimates, it decides how to route each portion across two or more processing devices.
The key word here is dynamic. Traditional inference deployments split a model at compile time — you decide upfront which layers go on which chip and that's that. This system can reassign portions at runtime based on what the metrics say. Think of it like a traffic management system that reroutes cars based on live congestion data, not yesterday's map.
The patent specifically mentions a "matene schedule inferencing" component (visible in the diagram), suggesting a scheduling layer that continuously evaluates and reassigns network portions. Multiple neural networks can be handled simultaneously, each with their own assignable portions (labeled Portion 140a and Portion 140b across different processing device groupings).
- Performance metric estimation — predicting cost or latency before committing a workload
- Dynamic partitioning — splitting network portions at runtime, not just at compile time
- Multi-processor coordination — orchestrating across two or more heterogeneous or homogeneous processors
What this means for multi-chip AI inference at scale
As AI models grow larger and inference demands increase, single-chip solutions hit hard ceilings. Multi-processor inference is already common in data centers, but the scheduling is often static — baked in during model deployment. A system that can dynamically rebalance based on live performance estimates could meaningfully reduce latency spikes and improve hardware utilization.
For Nvidia, this fits squarely into its broader push to make GPU clusters behave more like one giant, fluid compute fabric. If this approach makes it into production — whether in TensorRT, Triton Inference Server, or future NIM microservices — it could give Nvidia another layer of differentiation in the increasingly competitive AI inference market.
This is solid infrastructure work rather than a flashy AI capability. The real value is in the 'dynamic' part — static model partitioning is a known pain point for teams running large models across multi-GPU setups, and a runtime scheduler that estimates performance before committing could genuinely reduce the engineering burden of deployment. Worth watching for where Nvidia surfaces this in its software stack.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.