Nvidia Patents an Object Detection AI That Skips Fine Detail Without Losing Accuracy
Most object detection models process everything they see at every resolution — Nvidia's new patent argues you can skip the fine-grained layers entirely and still get accurate results, just faster.
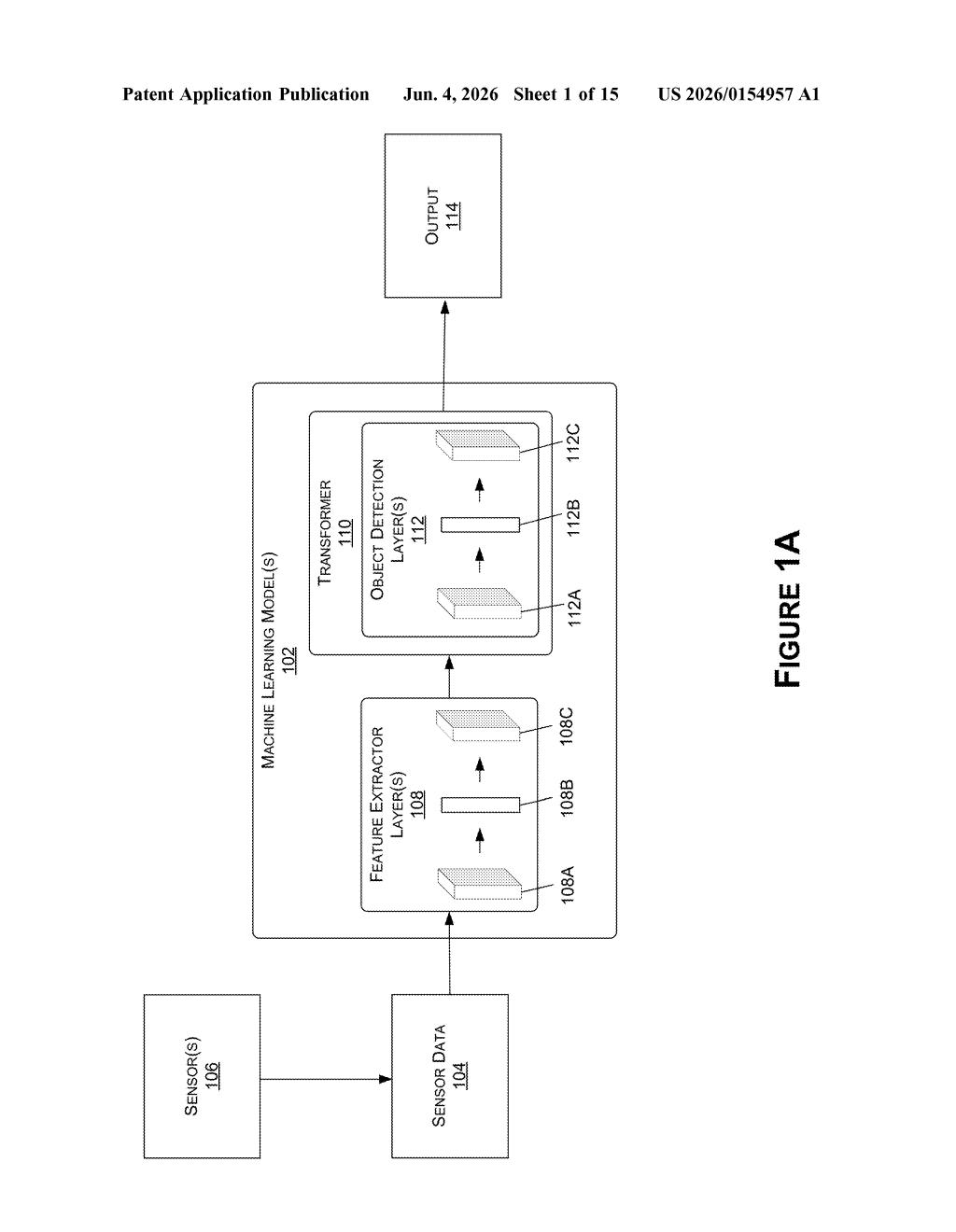
What Nvidia's selective feature-map trick actually does
Imagine your phone's camera trying to spot a stop sign. A typical AI model scans the image at several zoom levels — from wide-angle all the way down to pixel-level detail — before deciding what it sees. That's thorough, but it's also slow and computationally expensive.
Nvidia's patent describes a system that deliberately skips the high-detail zoom levels. Instead of feeding all the resolution layers into the decision-making part of the model, it only passes the lower-resolution feature maps — the broader, coarser views — into a transformer (the AI component that makes the final call on what's in the scene and where it is).
The bet is that for detecting objects like cars, pedestrians, or road signs, you don't actually need pixel-perfect detail to get the right answer. You just need enough context. By cutting out the expensive fine-grained data early, the system can run faster without a meaningful accuracy trade-off — which matters a lot when you're making split-second decisions in a moving vehicle.
How the backbone selects low-res maps for the transformer
The system is a classic detect-and-locate pipeline — it tells you what objects are in a scene and where they are — but it's been trimmed at a specific choke point.
First, a backbone network (the feature extractor, think of it as the model's eyes) processes raw sensor data — likely camera frames — and produces a set of feature maps at different resolutions. If four resolution levels are generated, you end up with one detailed fine-grained map and progressively coarser maps at lower resolutions.
The novel step: instead of handing all four feature maps to the next stage, the system selects only the subset associated with the lowest resolutions — the broadest views — and compresses them into a single vector (a compact numerical representation of the scene). Higher-resolution maps, which are computationally heavier to process downstream, are dropped.
That vector is then fed into a transformer (an attention-based neural network architecture, the same family of models powering large language models, but here applied to spatial reasoning). The transformer outputs a class label — "pedestrian," "vehicle," "cone" — and a bounding box location for each detected object.
The efficiency gain comes from keeping the expensive transformer stage lean: it processes a compact, low-res representation rather than rich multi-scale detail.
What this means for real-time autonomous perception
For autonomous vehicles and robotics, inference latency is not a nice-to-have — it's safety-critical. A perception model that runs 20% faster while maintaining detection accuracy can mean the difference between reacting in time and not. Nvidia sits at the center of the autonomous driving stack (its DRIVE platform powers many AV programs), so any patent that trims the object detection pipeline has a plausible path to a real product.
More broadly, this approach pushes back against the assumption that more detail always means better results. If low-resolution feature maps carry enough signal for reliable object detection, the industry could justify running leaner models on lower-power hardware — useful for edge devices, drones, or next-generation automotive SoCs where thermal and power budgets are tight.
This is a focused, practical optimization patent — not a conceptual moonshot. Nvidia is essentially formalizing the insight that transformers don't need full multi-scale feature inputs to do reliable object detection, and patenting the specific architectural choice of restricting inputs to low-resolution maps. It's the kind of quiet inference-efficiency work that actually ships into production systems, and the autonomous driving angle gives it real commercial weight.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.