Nvidia Patents a Parallel Attention-SSM Fusion Architecture for Faster Language Models
Nvidia is patenting an architecture that runs two fundamentally different AI memory mechanisms — attention heads and state space models — side by side in parallel, then fuses their outputs. The goal: get the best of both worlds without doubling the cost.
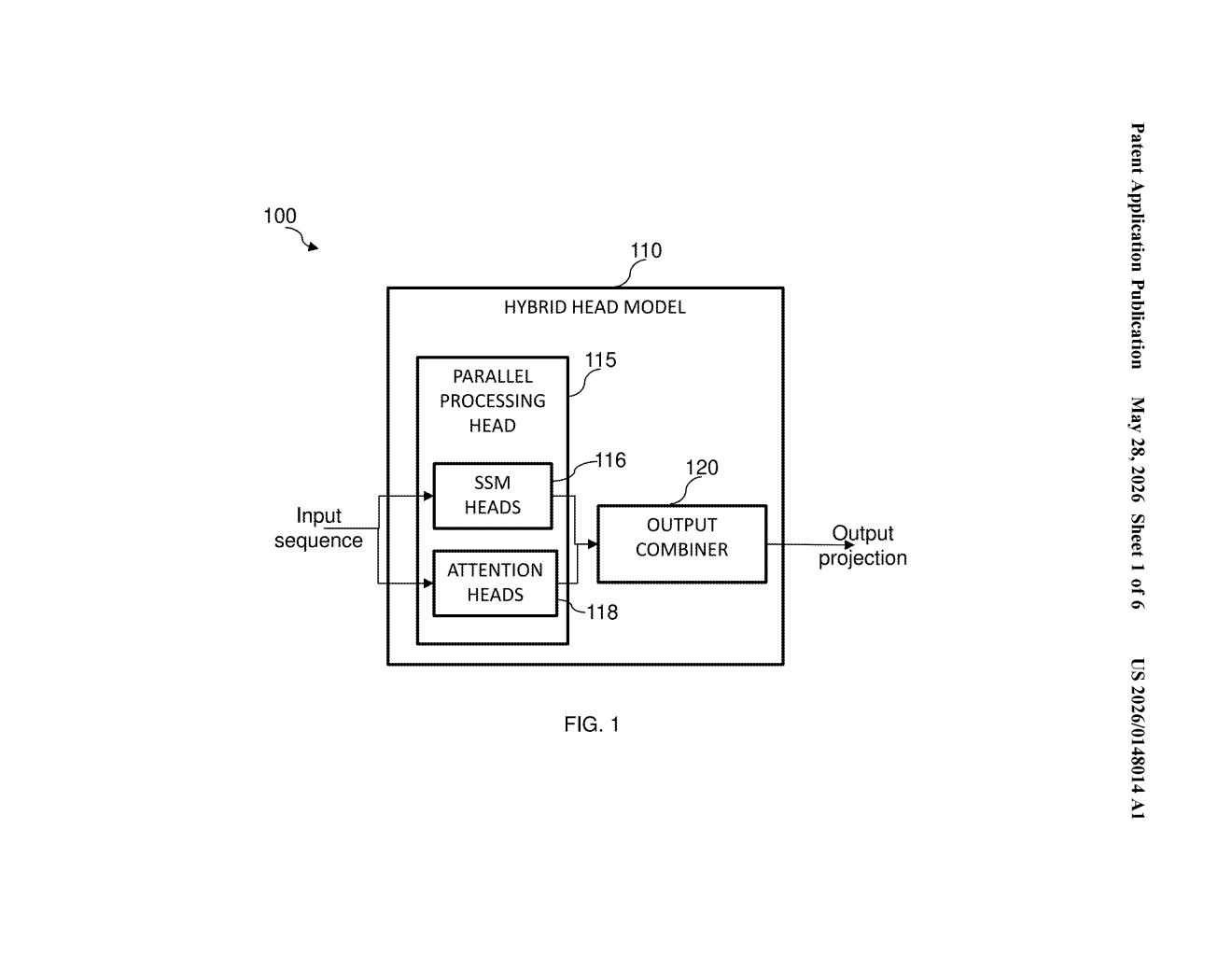
What Nvidia's hybrid attention-SSM language model actually does
Imagine you're trying to summarize a long book. One approach is to keep every sentence in memory and cross-reference them all constantly — thorough, but exhausting. Another is to maintain a rolling mental summary as you go — faster, but you might miss a detail from chapter one by chapter ten. Most modern AI language models use only the first approach.
Nvidia's patent describes a model architecture that runs both approaches at the same time. The attention heads handle precise recall across the whole input, while the state space model (SSM) heads handle efficient, compressed context — and their outputs are combined into a single result. The system also uses special "meta tokens" — a kind of learned shorthand — that help the model focus on what's actually important.
The upshot: you get better recall without paying the full memory and speed penalty that comes with pure attention-based models like standard Transformers. For tasks involving very long documents or real-time inference, that trade-off matters a lot.
How the parallel head fusion and meta tokens work together
The patent describes a hybrid-head model where each layer of a language model contains both attention heads (which compute relationships between every token in the sequence — the mechanism behind GPT-style Transformers) and SSM heads (state space models, which compress context into a fixed-size running state, similar to how Mamba or S4 models work). Crucially, both head types process the input in parallel rather than sequentially.
An output combiner then fuses the resulting vectors using an "algorithmic combination" — essentially a learned merge operation — to produce a single output projection per layer. This lets the model exploit the high-resolution recall of attention (great at remembering exact tokens far back in context) while also using the computational efficiency of SSMs (great at summarizing long sequences without quadratic memory costs).
Each layer can have its own ratio of attention-to-SSM heads, meaning the architecture is tunable per layer. The patent also introduces learnable meta tokens — trainable vector slots that act as a persistent, learned cache prepended to the sequence. These give both head types a compressed "cheat sheet" of salient information to attend to, reducing the burden on both mechanisms.
Additional techniques mentioned include KV sharing (reusing key/value vectors across heads to cut memory), layer normalization, and fine-tuning hooks — making this a fairly complete training and inference optimization framework, not just an architectural sketch.
What this means for next-gen LLM inference efficiency
Pure Transformer models scale poorly with sequence length because attention is quadratically expensive — double the context, roughly quadruple the compute. SSM models like Mamba sidestep this but can miss fine-grained details from earlier in a sequence. A fused architecture that parallelizes both and learns how to weight them is a real architectural bet that could make long-context inference significantly cheaper — important for coding assistants, document summarization, and agentic AI pipelines that need to hold a lot in working memory.
For Nvidia, there's an obvious downstream angle: if you design the training architecture, you can co-optimize it for your own hardware (think Blackwell GPU tensor cores and the NVLink memory fabric). A model architecture that runs parallel heads efficiently maps naturally onto GPU parallelism, giving Nvidia a potential edge in selling inference infrastructure tuned for models it helped define.
This is a substantive architecture patent, not a routine filing. The combination of parallel attention-SSM heads with learnable meta tokens addresses a real and widely-discussed limitation in long-context LLM inference. The inventor list includes several Nvidia Research heavyweights — this looks like serious work, not a defensive filing. Whether it becomes a standard architecture block depends on benchmark results, but the approach is grounded in current ML research directions.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.