Nvidia Patents a Layer-Wise Method to Compress Vision-Language Models
Training a powerful vision-language model takes enormous compute — but deploying one on a robot, a car, or a modest GPU is a different story. Nvidia's new patent describes a structured way to compress those large models down to size without gutting their capabilities.
How Nvidia shrinks big AI vision models without losing their smarts
Imagine you're trying to teach a junior chef by having them shadow a world-class cook. Instead of just copying the final dish, the junior chef watches every step — the knife technique, the seasoning timing, the plating style — and learns from each one. That's roughly what Nvidia's patent is doing with AI models.
The patent describes a training process where a large, capable AI model (the "teacher") helps train a much smaller model (the "student"). The trick is that learning happens not just from the final output, but at every layer inside the model — each intermediate processing stage gets matched up between teacher and student so knowledge transfers deeply and efficiently.
The goal is to end up with a compact vision-language model — the kind of AI that can look at an image and answer questions about it — that's small enough to run on edge devices or embedded hardware, but still punches well above its weight because it was trained so carefully.
How adaptive layer matching transfers knowledge layer by layer
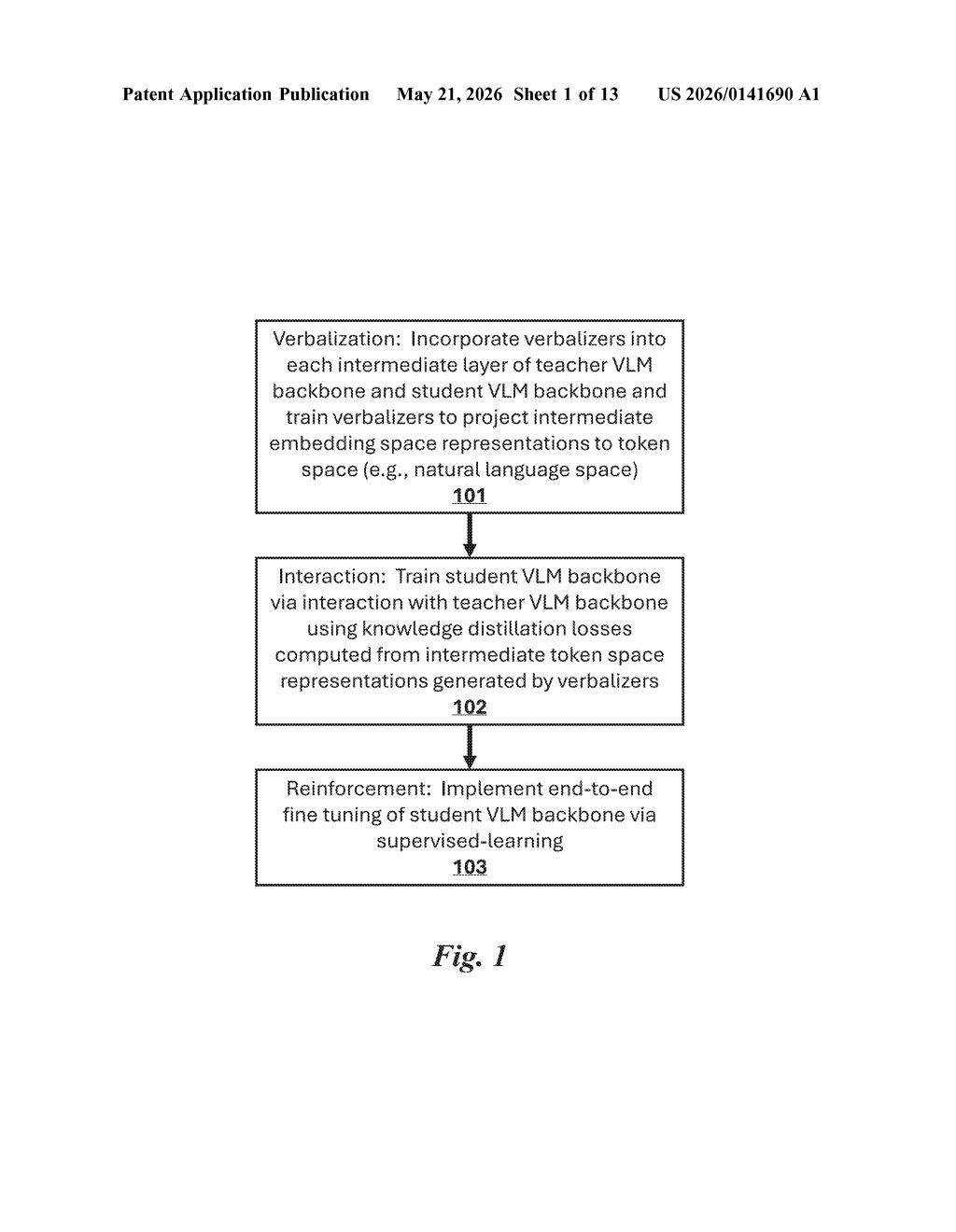
The patent introduces a three-stage training pipeline for compressing large vision-language models (VLMs — AI systems that understand both images and text together) into smaller, deployable versions.
The first stage, called verbalization, adds lightweight translator modules called verbalizers to every intermediate layer of both the teacher and student models. These verbalizers project the model's internal numerical representations (called embeddings) into natural language token space — essentially converting abstract internal states into something comparable in a shared vocabulary. This is what makes layer-to-layer comparison possible in the first place.
The second stage, interaction, is where the core distillation happens. The patent describes adaptive layer matching — a dynamic process that figures out which student layers should learn from which teacher layers, since the two models may have different depths. Knowledge distillation losses (a mathematical measure of how different the student's internal representations are from the teacher's) are computed and used to update the student model's parameters.
The third stage, reinforcement, is end-to-end supervised fine-tuning — a standard polish pass that locks in performance on downstream tasks. Together the three stages give the compact model not just the teacher's final answers, but a deep imprint of how the teacher reasons through a problem.
What this means for running vision-language AI on smaller hardware
Vision-language models are getting deployed in real products — robotics, autonomous vehicles, multimodal assistants — and in those contexts, model size is a hard constraint. A technique that lets a small model inherit the reasoning depth of a large one, rather than just mimicking its outputs, is genuinely useful engineering.
For Nvidia specifically, this fits squarely into their push to make AI inference efficient on their own edge and embedded platforms (Jetson, Drive, etc.). If this approach works as described, it could mean deploying capable multimodal AI in places where it previously couldn't fit — which is a practical win for the products their hardware powers.
This is solid, unglamorous AI infrastructure work — the kind of paper that quietly shows up in a model release changelog six months later. Layer-wise distillation isn't a new idea in deep learning, but applying it systematically to vision-language models with the verbalizer trick to bridge different architectures is a real contribution. Worth watching if you care about efficient AI on edge hardware.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.