Nvidia Patents an API That Kicks Off Matrix Math Before the Data Fully Arrives
Nvidia is patenting a way to let its processors start crunching matrix math before all the input data has even finished loading — shaving off idle time that currently sits at the heart of AI inference and training bottlenecks.
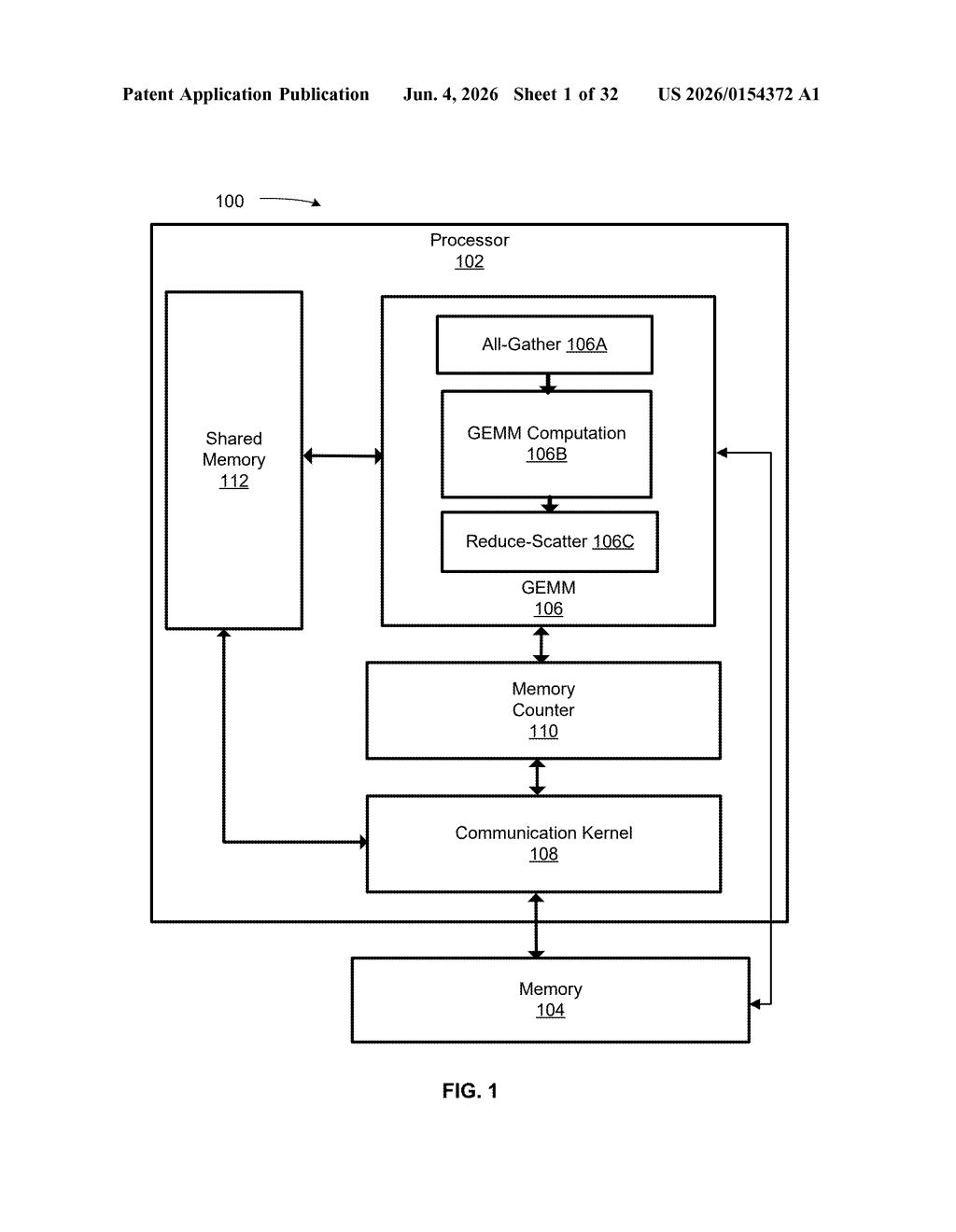
What Nvidia's partial-load matrix API actually does
Imagine a chef who waits for every single ingredient to be delivered before they even turn on the stove. That's roughly how most matrix multiplication works today: a processor loads all the numbers it needs, then starts computing. Nvidia's patent describes a smarter handoff.
The idea is to expose an API — a programming interface that lets software signal to the processor whether its input data has been only partially loaded. Instead of waiting for the full dataset to arrive, the processor can start working on the portions it already has.
For you, this mostly matters in the background: AI models running on Nvidia hardware could see better utilization of compute units that would otherwise sit idle waiting for memory transfers to finish. Less waiting, more doing — that's the core promise here.
How the GEMM pipeline acts on partially loaded operands
The patent centers on a processor that exposes an API call designed specifically for GEMM operations (General Matrix Multiply — the foundational math operation behind nearly every neural network layer). The API lets calling software communicate one critical piece of metadata: have the operands (the matrices being multiplied) been fully loaded into memory, or only partially?
Based on that signal, the processor can schedule partial GEMM operations — working on the data tiles that are already present rather than stalling the pipeline until a complete transfer finishes. This is a form of producer-consumer decoupling at the hardware instruction level.
- Normal flow: load all matrix data → compute full GEMM → output result
- Patented flow: load partial data → API signals partial availability → begin first GEMM portions → continue loading → complete remaining GEMM portions
The claim is deliberately broad — it covers any processor circuit that implements this API pattern, which suggests Nvidia is trying to protect the interface contract itself, not just one specific hardware implementation. The practical target is almost certainly their Tensor Core units, where memory bandwidth and compute throughput are in constant tension.
What this means for GPU throughput in AI workloads
Modern AI accelerators are often memory-bound: the compute units are fast enough that they spend meaningful time waiting for data to arrive from DRAM or HBM. Any technique that lets compute overlap with memory transfers directly improves hardware utilization — which translates to faster inference times and higher throughput per watt.
By patenting the API interface for this behavior rather than just an internal microarchitectural trick, Nvidia is also shaping how developers and compilers interact with its hardware. If this lands in CUDA or a future tensor instruction set, framework authors writing kernels for PyTorch or TensorFlow would need to use Nvidia's specific signaling pattern — keeping the ecosystem tightly coupled to Nvidia's toolchain.
This is unglamorous but genuinely useful chip plumbing. Memory latency hiding is one of the real remaining levers for squeezing more performance out of GPU silicon, and patenting it at the API layer rather than deep inside microarchitecture is a savvy move — it locks in Nvidia's interface as the standard before competitors can define their own. Don't expect a press release, but do expect this to quietly appear in a future CUDA release.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.