Nvidia Patents a Two-Stage Method for Teaching AI to See and Rebuild Images
Before an AI can generate a picture, it has to learn how to compress one. Nvidia's latest patent attacks that compression step from two angles at once, aiming for reconstructions that look far closer to the original.
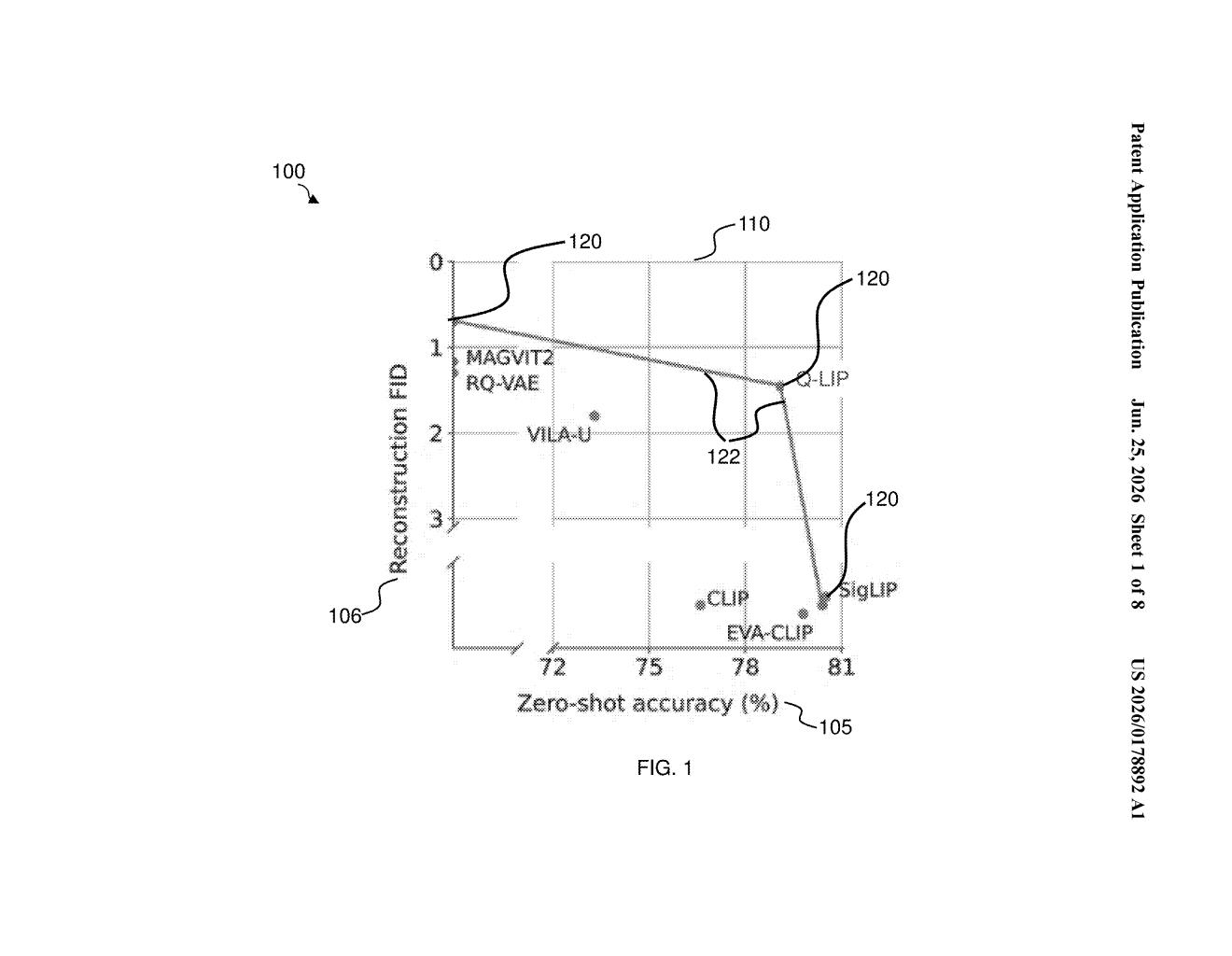
How Nvidia's image-compression pipeline actually works
Imagine you're packing a suitcase. In a rush, you stuff everything in loosely (stage one), then go back and carefully re-fold each item so it fits perfectly and nothing wrinkles (stage two). Nvidia's patent applies the same idea to the way AI systems compress images before generating new ones.
Most AI image models have to turn pictures into a compact set of numbers, called tokens, before they can do anything useful with them. If those tokens lose too much detail during compression, the AI's output looks blurry or off. Nvidia's approach splits the training process into two passes: a broad first pass that aligns text descriptions with images, and a focused second pass that polishes the compressed image tokens for maximum visual quality.
The result is a training pipeline called Q-LIP (Quantized Language-Image Pretraining) that tries to give AI models a more accurate visual "shorthand" to work from, which in theory means sharper, more faithful generated images and video frames.
Inside the Q-LIP two-stage training setup
The patent describes a training system called Q-LIP that teaches an AI model how to convert images and video frames into a compact, discrete set of numbers (tokens) without losing important visual detail.
- Stage one runs the text encoder and the visual encoder together on a large batch of image-text pairs. The goal here is alignment: making sure the numbers that represent a photo of a dog are close to the numbers that represent the words "a dog." This uses two loss functions (mathematical measures of how wrong the output is): an alignment loss and a mean square loss (which penalizes pixel-level differences).
- Stage two freezes both the text encoder and the visual encoder so they stop learning. The focus shifts entirely to a quantizer, a component that snaps the continuous image numbers into a fixed, discrete vocabulary, similar to how MP3 compression rounds audio samples. This stage uses a smaller batch size and optimizes for three combined loss signals: mean square loss, perceptual loss (how similar things look to a human eye rather than pixel by pixel), and a generative adversarial network (GAN) loss (a second AI that tries to tell real from fake, pushing quality higher).
- Finally, a transformer with an autoregressive model (the same basic architecture behind large language models) processes the discrete tokens to generate new images or video frames.
The key insight is that separating the alignment work from the fine-quality reconstruction work lets each stage focus on what it does best, rather than asking one training pass to juggle competing goals.
What this means for AI image and video generation
Image generation quality lives or dies on how well the compression step preserves visual information. If the tokens coming out of the encoder are muddy, no amount of downstream polish can fix it. By dedicating a separate training stage to perceptual and adversarial quality, Nvidia is trying to close the gap between what a model "remembers" about an image and what it actually looked like.
For you as an end user, better tokenization means AI tools that generate images and video with fewer artifacts, sharper edges, and more consistent details. This is directly relevant to Nvidia's ambitions in generative AI for video, robotics simulation, and any application where a model needs to both understand and reconstruct visual content accurately.
This is foundational plumbing work, not a flashy product announcement, but it's the kind of patent that matters. The two-stage training split is a concrete, testable idea that addresses a real bottleneck in generative AI quality. If Nvidia ships this inside a future version of its generative model stack, the improvement would show up in outputs, not in any visible interface change.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.