Nvidia Patents an AI System for Reading Depth From Two Camera Images
Your eyes judge distance by comparing what your left eye sees versus your right eye — and Nvidia is teaching AI to do the same thing, only faster and more precisely than before.
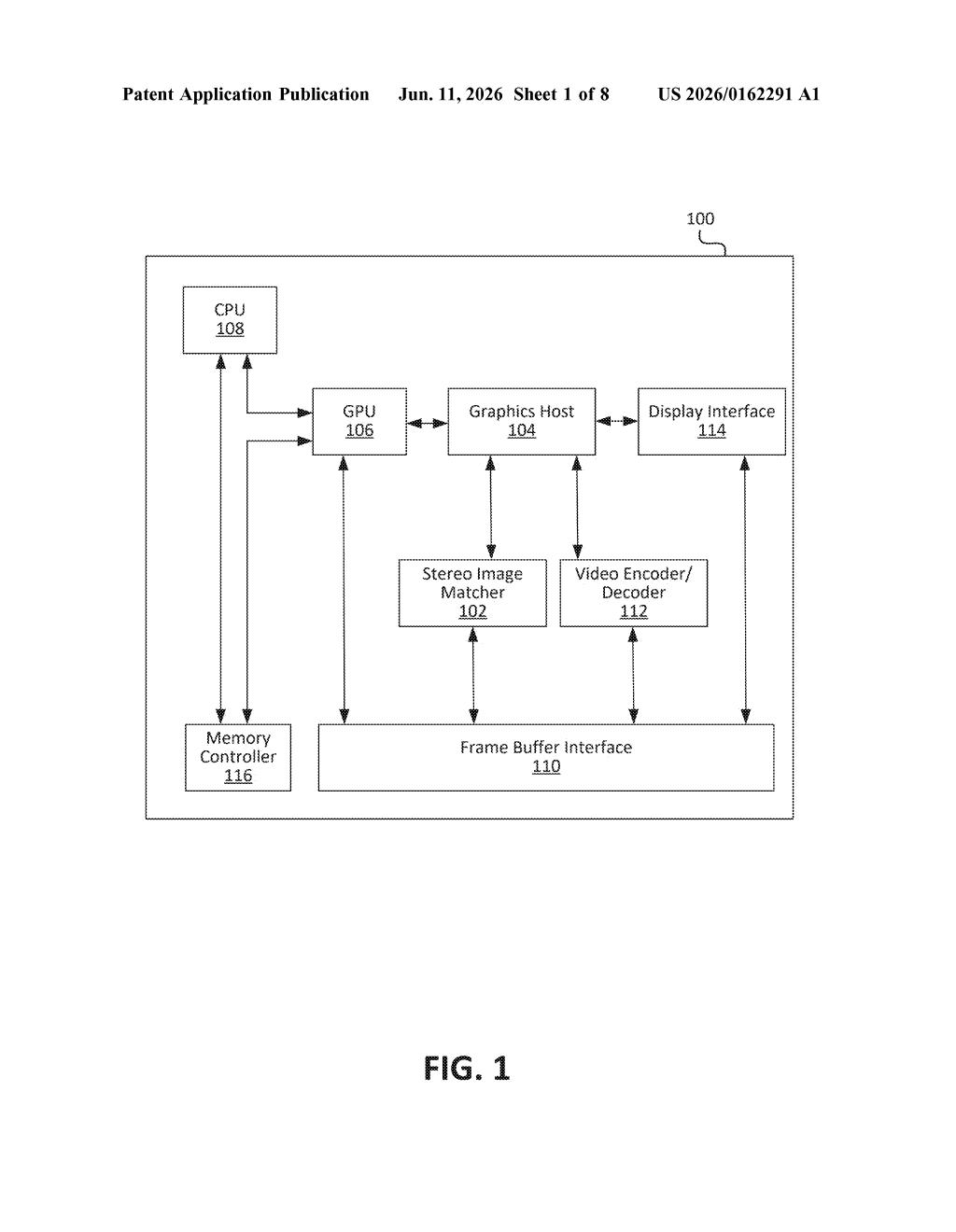
How Nvidia's AI figures out depth from two cameras
Think about how you'd judge how far away a coffee mug on a table is: your brain compares the two slightly different images your left and right eyes send it and uses that tiny difference to calculate depth. Cameras work the same way — two lenses positioned side by side capture a stereo pair of images, and software measures how far apart the same object appears in each shot. That gap is called disparity, and it's the key to building a reliable depth map of a scene.
Nvidia's patent describes an AI approach to making that depth calculation more accurate. For every single pixel in the image, a neural network looks at a range of candidate depth guesses and figures out how to weight and blend them into the best possible answer. Instead of picking one rigid depth value, it uses learned judgment to combine several possibilities.
This kind of depth estimation is fundamental to systems that need to understand 3D space from cameras alone — things like self-driving vehicles, robots navigating a warehouse, or AR headsets that need to know where objects actually are.
How the CNN refines pixel-by-pixel depth guesses
The patent describes a pipeline for estimating depth using a pair of cameras — a stereo image pair — by combining classical computer vision with a neural network.
The first step builds what's called a cost volume matrix. For every pixel in the left camera image, the system compares it against a range of candidate positions in the right camera image and scores how well each one matches. This produces a big table of match-quality scores, one row per pixel, across all the depth candidates being considered.
Next, classical stereo image processing (think: structured algorithms that aggregate those match scores across neighboring pixels to smooth out noise) runs on each pixel's entry in that table. This step outputs a set of intermediate disparity values — a shortlist of plausible depth guesses for that pixel.
Then comes the neural network step. A convolutional neural network (CNN) — a type of AI especially good at finding patterns in image-like data — takes that intermediate output and produces a set of weight values: essentially, how much trust to place in each candidate depth guess. The final disparity (depth) value for each pixel is calculated by combining the candidate values with those learned weights. The result is a disparity map: a full image where each pixel's brightness encodes how far away that point in the scene is.
What this means for self-driving cars and robotics
Accurate depth estimation from stereo cameras is a core challenge in autonomous driving, robotics, and any computer vision system that can't rely on expensive dedicated depth sensors like LiDAR. If your self-driving car or warehouse robot can extract reliable 3D geometry purely from camera images, it becomes cheaper and more versatile.
Nvidia is deeply invested in both autonomous vehicle platforms (Drive) and robotics (Isaac), so patents in this space fit a clear strategic direction. The approach described here — using a CNN to intelligently blend multiple depth candidates rather than committing to a single one — could reduce errors in tricky conditions like low-contrast surfaces, reflective materials, or repeated textures that tend to confuse traditional stereo algorithms.
This is solid, incremental computer vision engineering rather than a conceptual leap — but that's exactly the kind of work that matters in real-world autonomous systems where depth errors cost lives or crash robots. Nvidia filing this during a period of heavy investment in its robotics and autonomous driving platforms makes the timing purposeful, not coincidental.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.