Amazon Patents a Way to Strip Zeros Out of AI Model Weight Tables
AI models are packed with numbers that are literally zero — and Amazon wants its chips to stop wasting memory and time storing them.
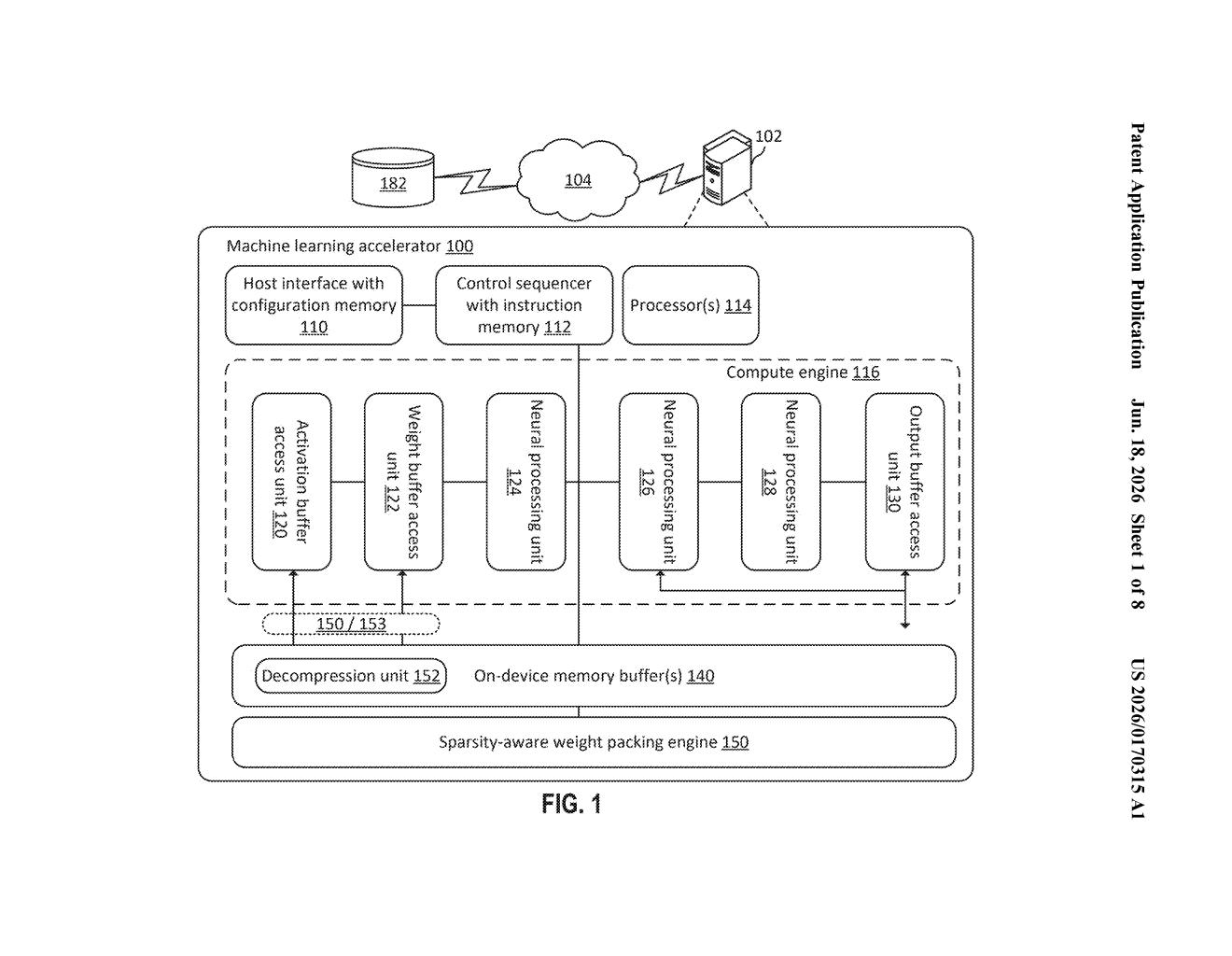
What Amazon's AI weight compression actually does
Imagine a massive spreadsheet with millions of numbers in it, but a large chunk of those numbers are just zeros — they don't actually change anything in a calculation. Carrying all those zeros around still costs memory and processing time. That's the situation Amazon is trying to fix with this patent.
The idea is to scan the weight tables inside an AI model — the stored numerical settings that define how the model thinks — and build a compact map that says which groups of numbers are all zeros and which aren't. The zeros get thrown out entirely; only the groups that contain real, non-zero values are kept. A small lookup chart (the "sparsity map") records where everything was, so the chip can reconstruct the full picture when it needs to.
The result is a smaller, leaner version of the model's data that takes up less space in memory and can move around a chip faster. It's a storage and speed optimization aimed squarely at the specialized AI hardware Amazon builds and operates.
How the sparsity map tracks which blocks get dropped
The patent describes a process for compressing weight tensors — the multi-dimensional arrays of numbers that define a trained neural network's behavior. These tensors are enormous, and in many trained models a significant fraction of values are exactly zero, a property called sparsity.
The system works in paired blocks. It looks at consecutive pairs (or larger groups) of elements in a weight tensor and classifies each block as either all-zero or containing at least one non-zero value. Each block gets a single bit in a sparsity map: a 0-bit means the block is all zeros and can be omitted; a 1-bit means the block has real data and must be kept.
- The all-zero blocks are dropped entirely from the stored data.
- The non-zero blocks are packed together into a compressed weight tensor.
- Both the compressed tensor and the sparsity map are written to memory on a neural network accelerator — Amazon's term for a dedicated AI chip.
When the chip needs to run a computation, it uses the sparsity map to know where the real blocks live and where to substitute zeros, reconstructing the full tensor on the fly. The net effect is that the chip reads less data from memory per inference pass, which reduces memory bandwidth pressure — one of the main bottlenecks on AI accelerators.
What this means for running AI on custom chips
Memory bandwidth is one of the hardest limits in AI hardware. The bigger and faster you want your model to run, the more data the chip has to shuffle around every second. Techniques that let a chip skip reading chunks of memory — without losing accuracy — translate directly into either faster inference or lower power draw, and often both.
Amazon operates Trainium and Inferentia, its own custom AI chips used across AWS. A sparsity-packing scheme baked into the chip's memory system could let those accelerators handle larger models or serve more requests per second without a hardware upgrade. For AWS customers paying by the compute-hour, that efficiency difference is real money.
This is unglamorous but genuinely useful chip engineering. Sparsity compression isn't a new concept — Nvidia's Ampere architecture introduced structured sparsity in 2020 — but the specific block-level packing scheme Amazon is patenting here is tailored to its own accelerator architecture. If it ships in a future Trainium or Inferentia generation, it's exactly the kind of low-level optimization that quietly lets Amazon price its AI compute more competitively.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.