Nvidia Patents AI That Repairs and Cleans Corrupted or Degraded Audio
Nvidia is patenting a general-purpose AI model that can clean up, restore, or isolate voices in an audio signal, and it's designed to be pretrained once and then adapted to many different audio tasks.
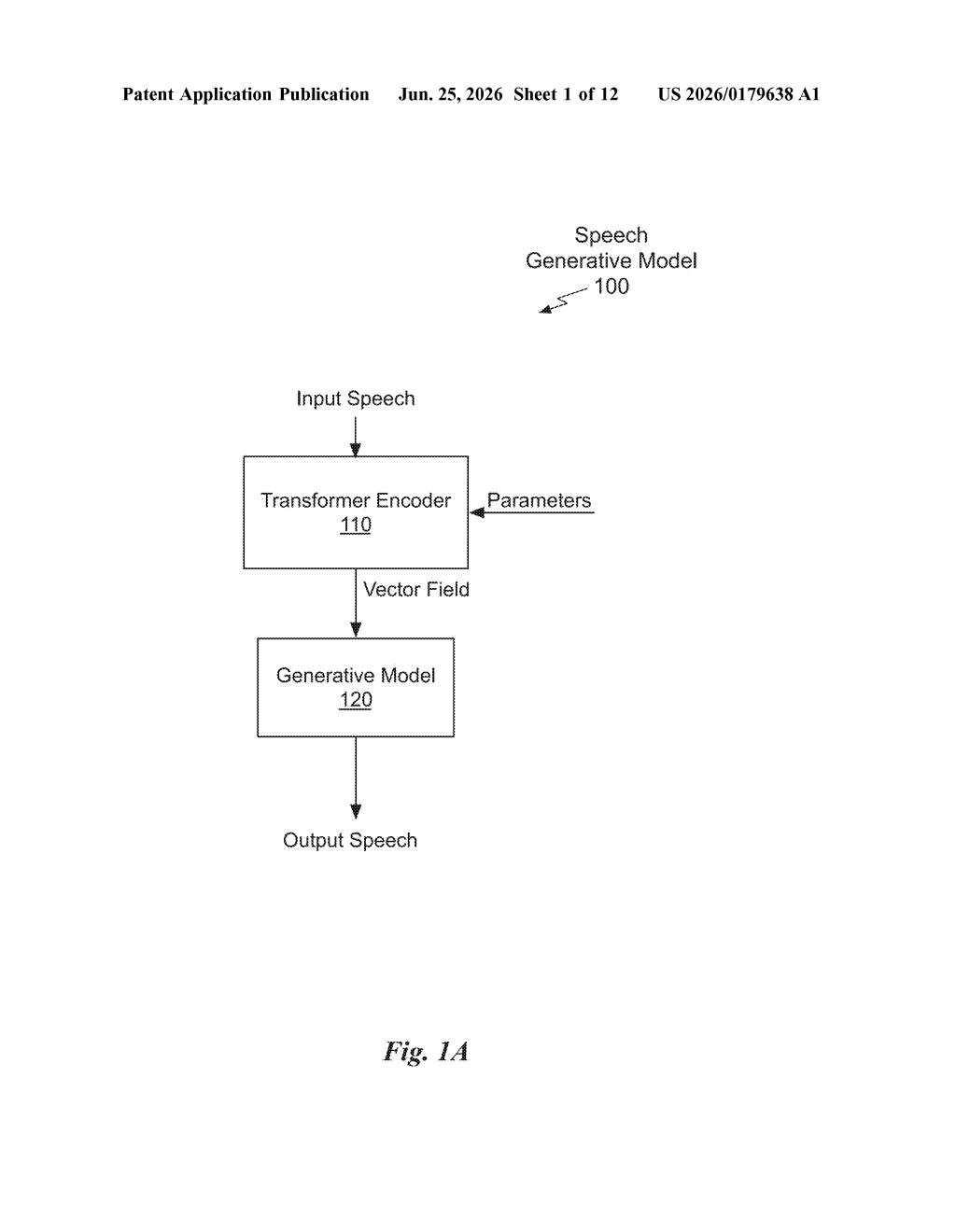
What Nvidia's audio restoration AI actually does
Imagine you're on a video call and your microphone picks up loud background noise, or a voice recording gets corrupted. Today, fixing that usually requires specialized software built for one specific problem. Nvidia's patent describes a different approach: a single, general-purpose AI model trained to understand speech at a deep level, which can then be fine-tuned to handle many different audio problems.
The system works by deliberately hiding parts of a speech signal, then training the AI to reconstruct what's missing. Over millions of examples, the model learns what clean, natural speech sounds like, without needing anyone to hand-label the training data.
Once trained, the same base model can be adapted to tasks like removing background noise, separating one speaker's voice from a crowd, or repairing audio that's been compressed or degraded. Think of it like a general medical scanner that can be recalibrated for different types of scans, rather than needing a separate machine for each one.
How the masking and invertible transform pipeline works
The patent describes a generative speech foundation model, an AI trained broadly on unlabeled speech data that can later be fine-tuned for specific audio restoration or extraction tasks.
The technical pipeline works in three stages:
- Masking: portions of the input speech signal are deliberately hidden or zeroed out, similar to how text AI models like BERT are trained by masking words.
- Transformer processing in an invertible domain: the masked signal is passed through a transformer-based neural network (the same family of architecture behind modern language models) which operates not on the raw audio waveform but on a mathematically transformed version of it, a space where the structure of sound is easier to manipulate. The model produces a vector field of coefficients (a set of values describing how the signal should be reconstructed).
- Inverse transform: those coefficients are converted back into a real audio waveform using the mathematical inverse of the original transform, producing restored audio.
The model is first pretrained on large amounts of unlabeled audio, no human annotations needed, and then fine-tuned on smaller labeled datasets for specific tasks like noise suppression, speaker extraction, or audio super-resolution.
What this means for real-time audio and voice tools
The foundation model approach is well established in text AI (think GPT-style pretraining) but applying it to audio restoration is less mature. If Nvidia can train a single powerful base model for speech, the cost of building specialized audio tools drops significantly because you start from a strong base rather than from scratch each time.
For Nvidia, this fits naturally into its push to run AI workloads on its hardware, including real-time audio processing in conferencing, gaming, broadcasting, and voice assistants. Tools like Nvidia RTX Voice and Broadcast already do noise suppression on consumer GPUs, and a foundation-model approach could make those tools more adaptable and capable without rebuilding them entirely for each new use case.
This is a technically solid idea that mirrors what the text AI world learned several years ago: pretraining a large general model and fine-tuning it is almost always more efficient than training task-specific models from scratch. Nvidia applying that lesson to audio restoration is sensible, not flashy, and it fits squarely into what the company is already selling with its Broadcast and RTX audio tools.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.