Waymo Patents an LLM System That Predicts What Self-Driving Cars Will See Next
Waymo is patenting a system that makes its self-driving car describe what it sees in plain text — then uses those text descriptions as inputs to a separate neural network that predicts what's about to happen on the road.
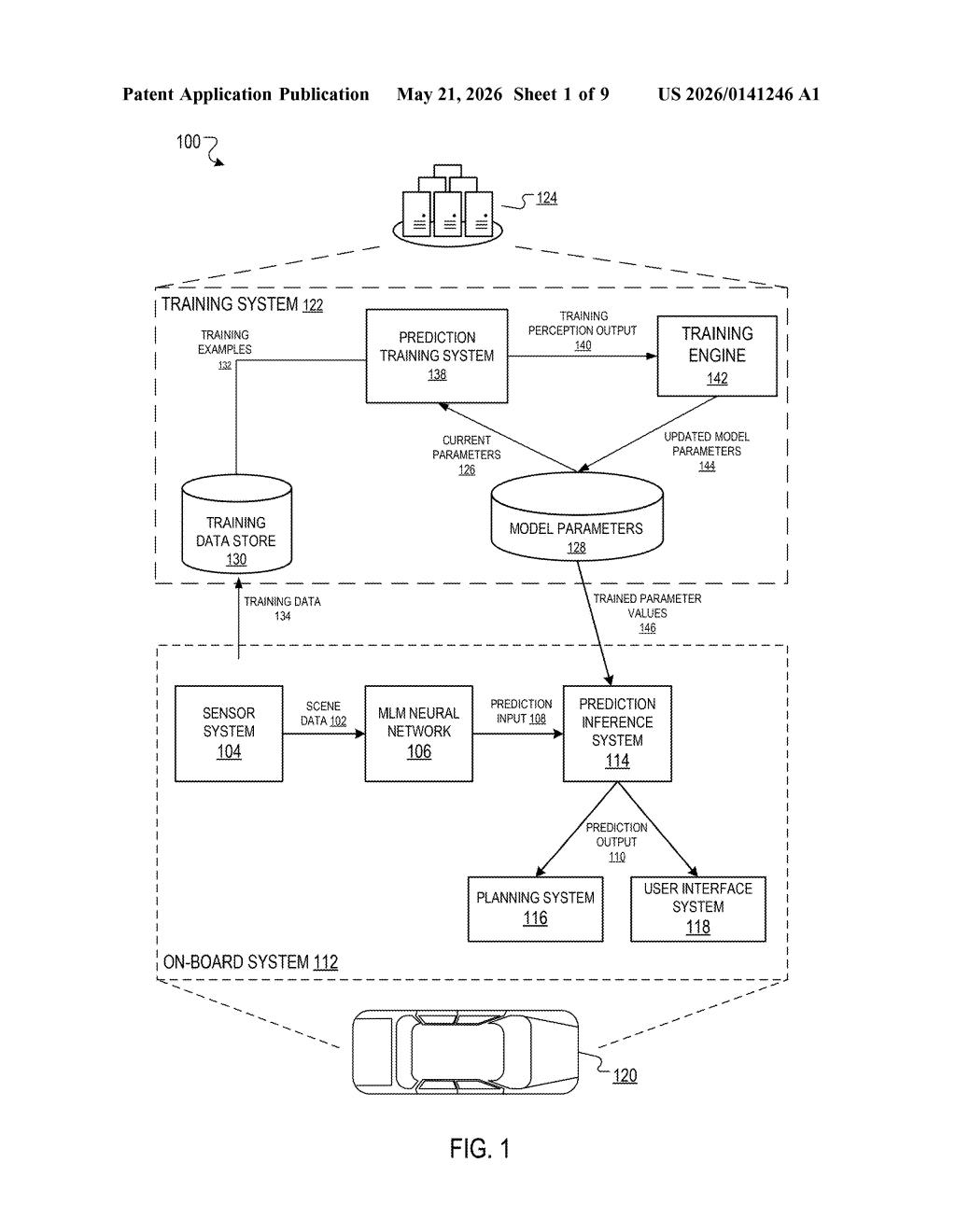
What Waymo's LLM-assisted scene prediction actually does
Imagine a self-driving car approaching a busy intersection. Instead of just feeding raw camera and lidar data into a prediction model and hoping for the best, Waymo's system first has a language model describe the scene in words — something like 'a cyclist is signaling left near a stopped bus' — and then passes that description alongside the raw sensor context into a second model that figures out what everyone is likely to do next.
The key idea is that large multimodal language models (think GPT-4V-style systems that understand both images and text) are already very good at interpreting complex visual scenes. Waymo wants to tap into that capability as a scene understanding layer that sits upstream of its dedicated prediction system.
The result is a two-stage pipeline: an LLM that reads the world and narrates it, and a prediction network that uses that narration — plus raw sensor context — to forecast how pedestrians, cyclists, and other vehicles will behave. You get the language model's broad world knowledge combined with the prediction model's precise trajectory-forecasting ability.
How the MLM converts sensor data into prediction inputs
The patent describes a multimodal language model (MLM) neural network — a model that can process visual inputs like camera frames alongside text — generating one or more text outputs that describe what's happening in a driving scene at a given moment.
Those text outputs are then combined with scene context data (structured information about the environment: road geometry, traffic signals, agent states, etc.) to form a prediction input to a separate, dedicated prediction neural network. That second network is what actually outputs predictions — think trajectory forecasts for every agent (pedestrian, cyclist, car) in the scene.
The architecture is deliberately modular:
- Sensor data (camera, lidar, radar) goes into the MLM, which narrates the scene in natural language.
- Those text descriptions are fused with structured scene context data.
- The combined input is processed by a prediction network tuned specifically for trajectory or behavior forecasting.
This separation matters because the MLM handles open-ended scene interpretation — it can describe unusual or ambiguous situations in a way that rigid perception pipelines might miss — while the prediction network focuses on the precise, safety-critical task of forecasting motion. The training system described in the patent also allows the prediction network's parameters to be optimized using perception outputs from training data, keeping both stages jointly grounded.
What this means for how self-driving cars understand the world
Self-driving prediction models have historically struggled with rare or ambiguous scenarios — the edge cases that structured sensor pipelines can't reliably classify. By routing scene understanding through an LLM first, Waymo is betting that language models' exposure to vast amounts of real-world visual and textual data gives them a richer, more generalizable grasp of what's actually happening on the road — especially in weird situations a narrow perception model might misread.
For Waymo's commercial robotaxi operations, better scene prediction directly translates to smoother, safer rides. If this pipeline proves robust, it also hints at a broader architectural shift: using foundation models not as end-to-end drivers, but as interpretive middleware that feeds specialized downstream models — a design pattern that could show up across the autonomous driving industry.
This is a genuinely interesting architectural bet. Rather than trying to make one giant model do everything, Waymo is threading LLM scene understanding into an existing prediction pipeline as a discrete, swappable layer. That modularity is practical engineering, not flashy AI branding — and it lines up with how serious ML teams actually ship safety-critical systems. Worth watching closely as the multimodal model space matures.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.