Microsoft Patents a System for Controlling Which Data Feeds Your LLM's People Profiles
When an AI generates a bio or summary about a real person, it pulls from data sources you may never have chosen or approved. Microsoft's new patent wants to put a control panel in front of that process.
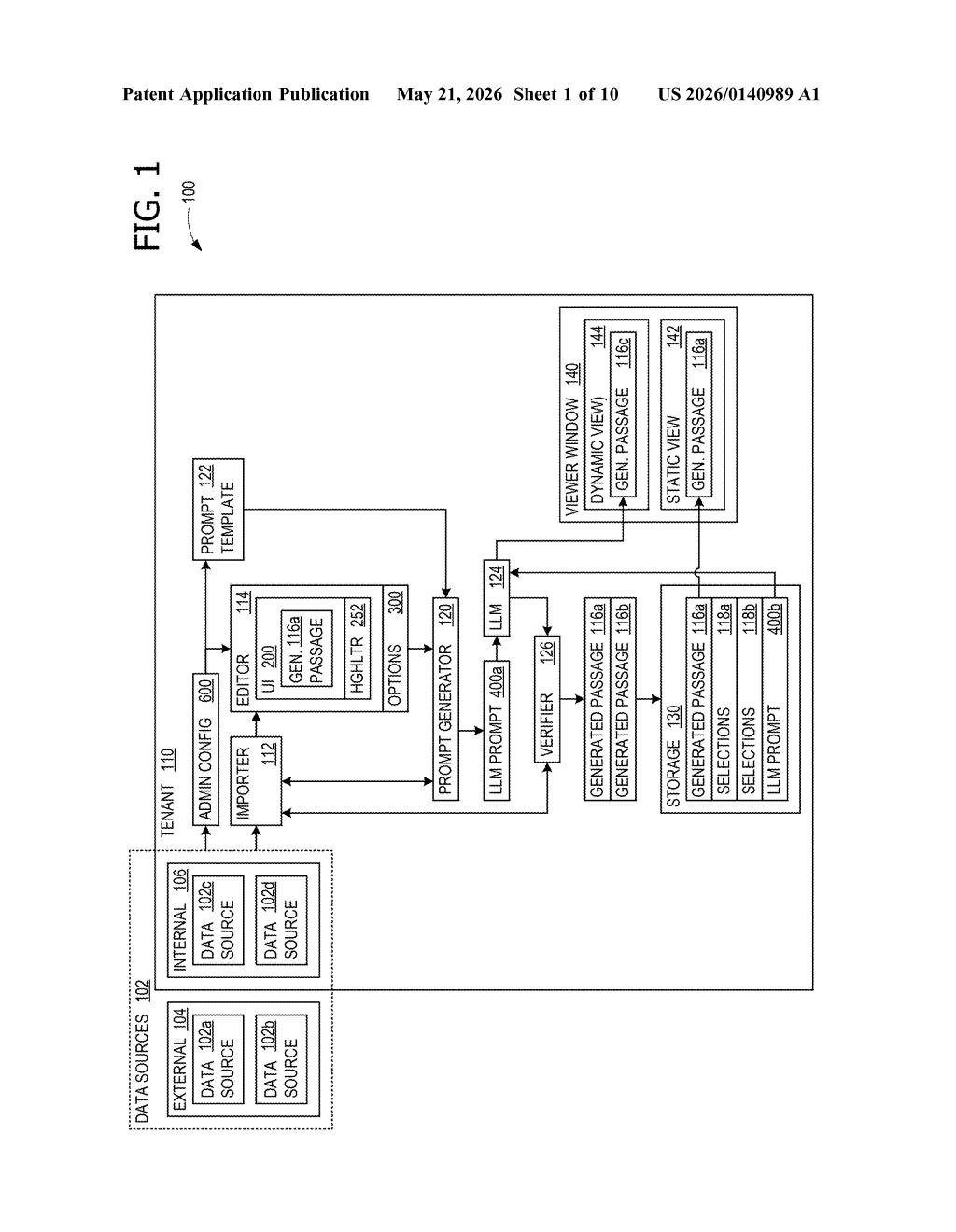
What Microsoft's data-source curation system actually does
Imagine your company uses an AI assistant to generate quick profiles or summaries about employees, clients, or contacts — pulling from LinkedIn, internal HR records, a CRM, and a calendar. Right now, you probably have little say in which of those sources the AI actually uses. Microsoft's patent describes a system that gives users — or admins — a clear interface to toggle each data source on or off before the AI generates anything.
The clever part is something called viewer classes. Different audiences (say, a manager vs. a colleague vs. an external recruiter) can see AI-generated passages built from different sets of approved data sources. A recruiter's view might only pull from public data; a manager's view might include internal performance notes. You explicitly approve what gets used, and that approval is logged.
When any of those underlying data sources updates — a new LinkedIn post, a changed job title — the system automatically refreshes the relevant passages. So the AI-generated text stays current without anyone having to manually re-run the prompt.
How viewer classes gate data into LLM-generated passages
The patent describes a UI component called a viewer class selection window. When someone wants to generate an LLM-authored passage about a person, this window presents a first set of selected data sources (a baseline or default list) alongside a second set (the active, customizable list for a specific viewer class).
Each entry in the second set maps one-to-one to an entry in the first set via a data source identification. The second set carries a flag indicating whether that data source should actually be used in generation — effectively a per-source on/off toggle keyed to audience type.
The system then:
- Detects changes the user makes to that second set
- Waits for an explicit approval signal before generating anything
- Persists a record of that approval (important for audit trails in regulated environments)
- Generates the passage and displays it
- Automatically refreshes existing passages when upstream data sources change
The refresh mechanism is notable: it's tied to both the first set (baseline) and the second set (viewer-specific), meaning all audience-scoped views stay in sync with live data without re-prompting. The patent also distinguishes between dynamic views (auto-refreshed) and static views (snapshot at approval time), giving users control over staleness.
What this means for AI-generated profiles and privacy compliance
Privacy regulations like GDPR and CCPA increasingly require that organizations justify which data they process about individuals and why. An AI that silently hoovers up every available data source to write a person's profile is a compliance liability. This patent addresses that directly by building approval records and audience-scoped data permissions into the generation loop itself — not as an afterthought.
For enterprise products like Microsoft 365 Copilot, which already generates summaries about people from email, calendar, and org-chart data, this kind of architecture would let IT admins and end users define exactly what feeds those summaries depending on who's asking. It's less about the AI being more capable and more about making its data consumption auditable and controllable — which is increasingly what enterprise buyers actually want.
This is unglamorous but genuinely useful infrastructure work. The hard problem of LLM-generated content in enterprise settings isn't intelligence — it's provenance and consent, and this patent takes a concrete architectural swing at both. If this ships into Copilot or a similar Microsoft product, privacy and compliance teams will care about it a lot more than product reviewers will.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.