Microsoft Patents a Self-Healing Agent That Fixes Broken Plugins Without Stopping
What if your software agent could figure out which part of itself was broken — and fix just that part — without you ever noticing a hiccup? That's what Microsoft is building with this patent.
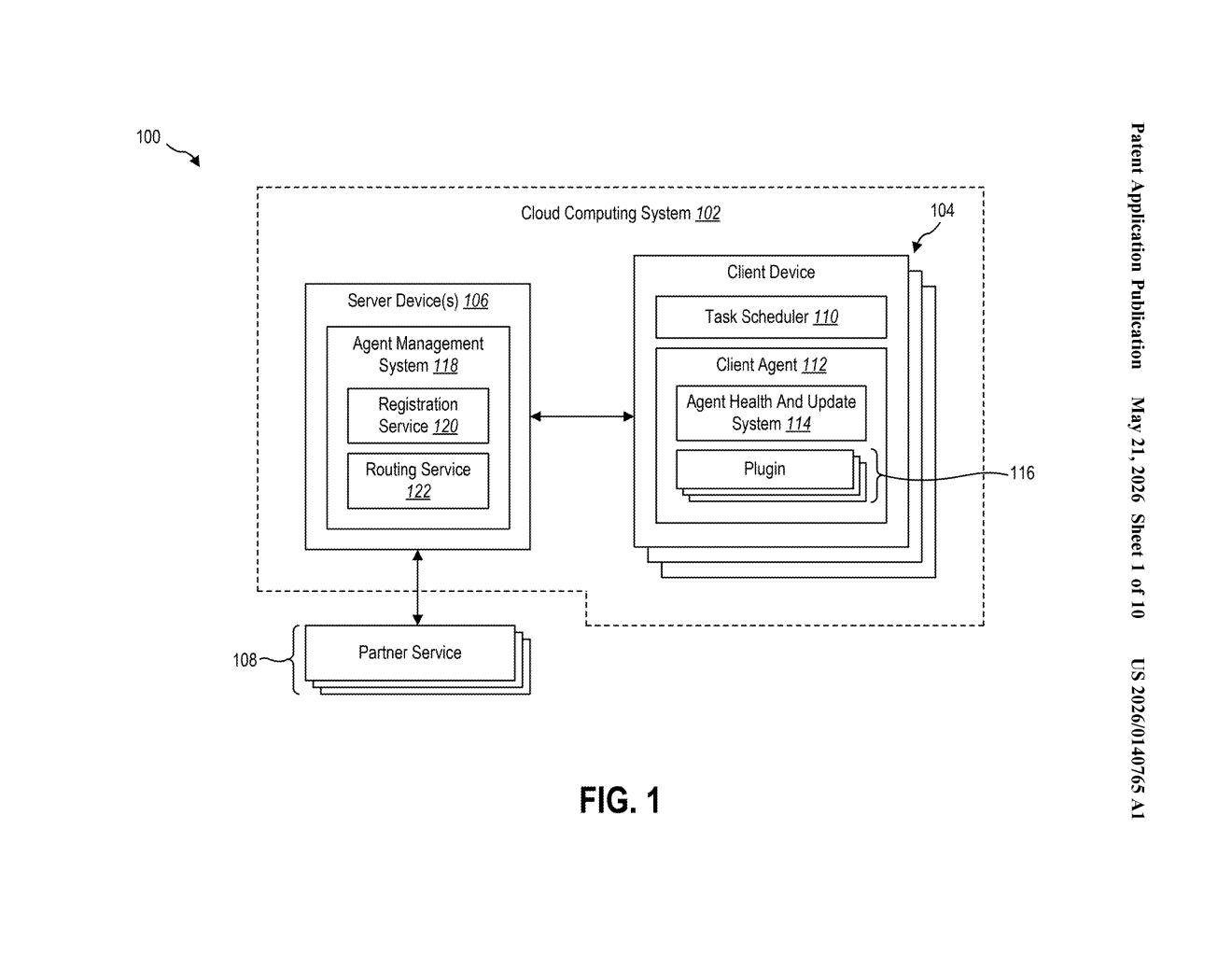
How Microsoft's plugin isolation and self-repair actually works
Imagine a Swiss Army knife where each tool has its own handle. If the scissors jam, you can still use the blade, and the knife itself figures out which tool is faulty and tries to fix it. That's roughly the idea behind this Microsoft patent.
Microsoft is describing a client agent — think of it as background software running on your PC or a virtual machine — that's built out of isolated, swappable plugins. Each plugin handles a specific function and runs in its own lane so that one misbehaving plugin can't crash the others.
The clever part is the self-healing logic. The agent can deliberately pause one plugin at a time to see whether overall performance improves. If things get better when Plugin A is paused but not when Plugin B is paused, the system concludes Plugin A is the culprit and takes corrective action — all without a human having to diagnose anything.
How the health monitors pinpoint which plugin is misbehaving
At the core of this patent is a plugin-based client agent where each plugin runs in an isolated thread (a separate lane of execution), meaning one plugin can't directly interfere with another's memory or state.
Overseeing everything is a three-tier health-monitoring stack:
- Device Health Monitor — watches the overall health of the host machine
- Agent Health Monitor — tracks resource consumption (CPU, memory, etc.) at the agent level
- Plugin Health Monitor — observes the behavior of individual plugins
The real intelligence lives in the binary-search-style fault isolation logic described in the claim. The scheduler can suspend Plugin A while keeping Plugin B running, then check a policy determination — basically a yes/no verdict on whether the agent is now within acceptable operating boundaries. It then does the reverse. By comparing the two results, the system can triangulate which plugin is violating policy and trigger a corrective action (which could mean restarting, rolling back, or replacing that plugin).
All behavior is governed by policy data stored locally, giving IT administrators a way to define what "healthy" looks like and how aggressively the agent should respond to violations.
What this means for enterprise software reliability
For enterprise IT, the biggest headache with background agents — things like endpoint security tools, monitoring daemons, or management clients — is that a single buggy update can take down the whole agent, leaving a machine unmanaged or unprotected. This architecture sidesteps that by making partial failure the default, not full outage.
For end users, this is largely invisible infrastructure — and that's the point. If Microsoft deploys this in something like Microsoft Intune or its endpoint management stack, you'd simply never notice that a plugin crashed and repaired itself overnight. IT teams, though, would see fewer emergency rollbacks and support tickets tied to agent failures.
This is unglamorous but genuinely useful systems engineering. The binary-isolation trick for fault diagnosis is clean, and the three-level health monitor hierarchy shows real design thought. It's squarely aimed at Microsoft's enterprise device-management business, where agent reliability is a daily pain point — so expect this to show up in Intune or a similar product rather than sit on a shelf.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.