Amazon Patents a System That Ties Voice Commands to What's on Your Screen
Saying 'add that to my cart' to a voice assistant only works if the assistant knows what 'that' actually is. Amazon's latest patent describes a system that figures it out by reading what's currently on the screen.
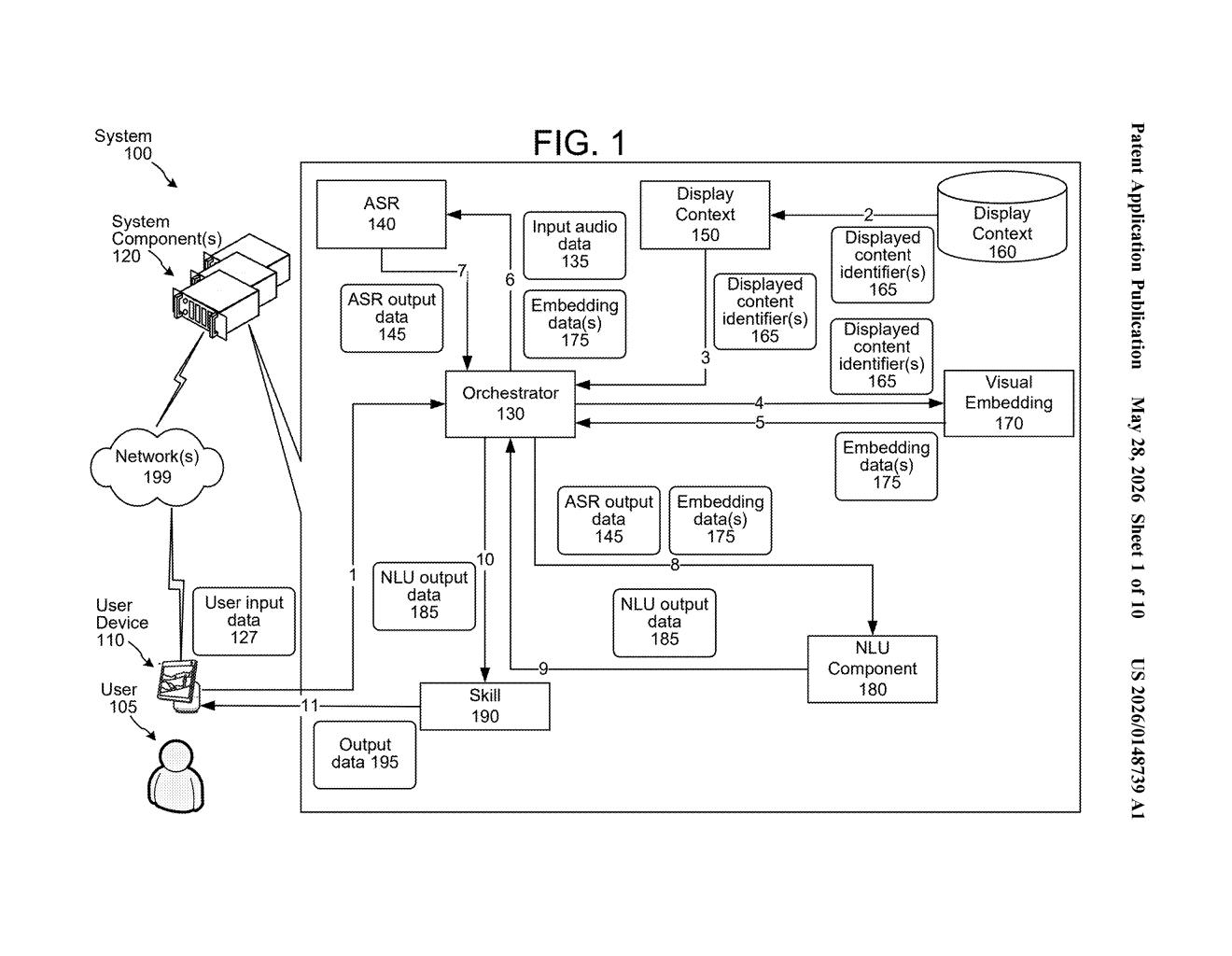
What Amazon's screen-aware voice command system actually does
Imagine you're browsing a product page on your Fire TV and you say, 'Tell me more about this.' Right now, most voice assistants would either ask for clarification or just search the internet — they don't really know what this refers to. Amazon's patent describes a system that solves that problem.
The idea is straightforward: before you even speak, the device is quietly tracking what content is displayed on screen. When you do say something, the system combines what you said with a rich digital fingerprint of the on-screen content — called an embedding — to figure out exactly which part of the screen your question is about.
So if a movie title and a cast member's name are both visible, and you ask 'who directed this?', the system can correctly anchor your question to the right portion of the displayed content rather than guessing. It's the difference between a voice assistant that actually pays attention and one that's just waiting for a keyword.
How Amazon maps speech to on-screen content with embeddings
The patent describes a pipeline that bridges natural language understanding (NLU) — parsing what you said and what you meant — with visual context from the display.
Here's the core flow:
- Content is being shown to the user on a screen (a TV, tablet, or similar display device).
- The system tracks content identifiers — essentially references to what's currently visible.
- From those identifiers, it generates embedding data (a numerical representation that captures semantic features of the content, think of it as a fingerprint that knows what a piece of content 'means').
- When the user speaks, the system runs NLU on the audio to get a natural language interpretation — the user's intent and what they're asking about.
- The NLU output and the embedding data are processed together to determine which specific portion of the displayed content the spoken input refers to.
- An action is then performed based on that matched portion.
The key insight is disambiguation. If two pieces of content are on screen simultaneously — say, a product listing and a sponsored ad — the system doesn't just match a keyword. It uses the embedding representation to resolve which one the user's phrasing most likely refers to, then acts on that determination.
What this means for Alexa and ambient computing devices
For Amazon, this is plumbing for a more capable ambient computing layer. Alexa-enabled screens — Fire TV, Echo Show, Fire tablets — become dramatically more useful if Alexa understands conversational references like 'that one' or 'the second item' without needing users to repeat product names verbatim. That's the friction that stops people from actually using voice for shopping or content discovery.
More broadly, this signals Amazon's intent to make voice interaction context-aware by default rather than as an opt-in feature. If the system ships at scale, it closes a gap that has made voice assistants feel clunky compared to just tapping a screen — and it does so without requiring users to change how they speak.
This is genuinely useful infrastructure work, not flashy AI theater. The problem of grounding spoken language to visual context is a real friction point that holds back voice-first interfaces — Amazon is right to tackle it. The continuation filing structure suggests the core approach (US 12,494,200) is already patented and this is an extension, which means Amazon is serious about building a moat around this capability.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.