Adobe Patents a System for Generating Consistent Characters Across AI Scenes
One of the most frustrating problems with AI image generators is that your character looks like a completely different person from one prompt to the next. Adobe is filing a patent that tries to fix that at the model level.
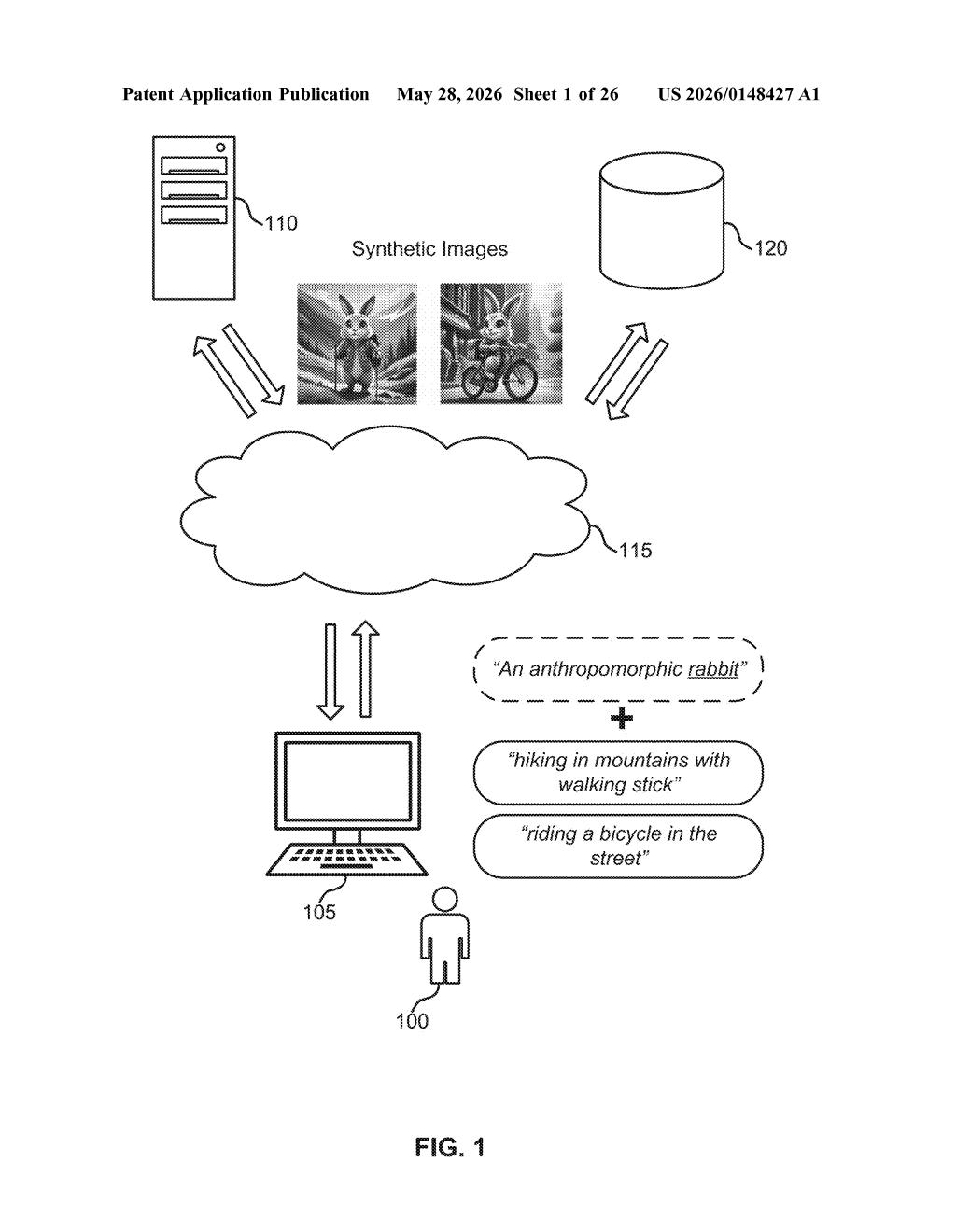
What Adobe's cross-scene character consistency actually does
Imagine you're creating a short comic strip using an AI image tool. You type one prompt to show your hero hiking in the mountains, and another to show them riding a bicycle in the street. But when the images come back, the character looks totally different in each one — different face, different build, different hair. That's the problem Adobe is trying to solve.
Adobe's approach generates both images at the same time rather than one after another. By processing your two prompts together, the system can make sure the character in scene one and the character in scene two are recognizably the same person.
This matters most for creators who need visual consistency — think storyboards, children's books, marketing campaigns, or social media content. Instead of spending hours prompting and re-prompting to get a character to look right, this system does the consistency work for you automatically.
How Adobe's cross-image attention locks character identity
The core idea is a technique called cross-image attention. In standard AI image generation, each prompt is processed independently — the model has no reason to make character A in image one look like character A in image two. Adobe's patent changes that by feeding both prompts into a shared attention process simultaneously.
Attention mechanisms (the same foundational concept behind large language models) let a neural network figure out which parts of the input are most relevant to each other. Here, by running a cross-image attention pass, the model can align visual features — face shape, clothing style, body proportions — across both outputs before either image is fully rendered.
The process works roughly like this:
- Obtain two text prompts describing the same object or character in two different scenes
- Run both prompts through the image generation model together using a cross-image attention layer
- The model produces two attention outputs, each informed by both prompts
- Two synthetic images are generated from those paired attention outputs, keeping the character consistent
The patent is written broadly enough to apply to any object, not just human characters — so a branded product, a pet, or a vehicle could theoretically be kept visually consistent across scenes using the same method.
What this means for AI-generated comics and branded content
For creative professionals using Adobe's Firefly platform, this would be a meaningful quality-of-life upgrade. Character consistency is one of the last big friction points in AI-assisted visual storytelling — it's why most AI-generated comics today still feel like a visual non-sequitur from panel to panel. A model-level fix, baked into the generation step rather than bolted on after, is a cleaner solution than existing workarounds like ControlNet reference images or face-locking plugins.
For brands and marketers, consistent characters mean usable assets. If Adobe ships this in Firefly, it could make AI image generation genuinely practical for campaign work — not just one-off illustrations but cohesive visual series with a recognizable protagonist.
This is a real problem that anyone who's used Midjourney or Firefly for more than five minutes has run into, and Adobe's approach — solving it inside the attention mechanism rather than as a post-processing hack — is the right architectural instinct. The patent is broad, but the underlying idea is sound and directly tied to Adobe's Firefly roadmap.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.