Qualcomm Patents a Way to Run AI Calculations Inside the Memory Chip Itself
One of the biggest drags on AI performance is simply moving numbers back and forth between memory and a processor. Qualcomm's latest patent describes a chip design that skips much of that shuffle by doing the math right where the data lives.
What Qualcomm's in-memory AI math actually does
Imagine you're baking and every single ingredient is stored in a warehouse across town. Every time you need flour, you have to drive over, grab it, drive back, and then use it. That's roughly how most AI chips work: data sits in memory, gets hauled to a separate processor, gets calculated, then gets sent back. It's slow and power-hungry.
Qualcomm's patent describes a different setup: a processing-in-memory chip that does the math inside the memory itself, so the ingredients never need to leave the warehouse. The chip handles the giant multiplication tables that AI models like ChatGPT rely on, applies the necessary compression adjustments (called scaling factors), and pipelines the work so that while one batch of results is being read out, the next batch of calculations is already running in parallel.
The practical payoff is that you could run a large language model faster and with less energy, which matters a lot if the goal is to get that kind of AI working on a phone or a small device rather than a massive data-center server.
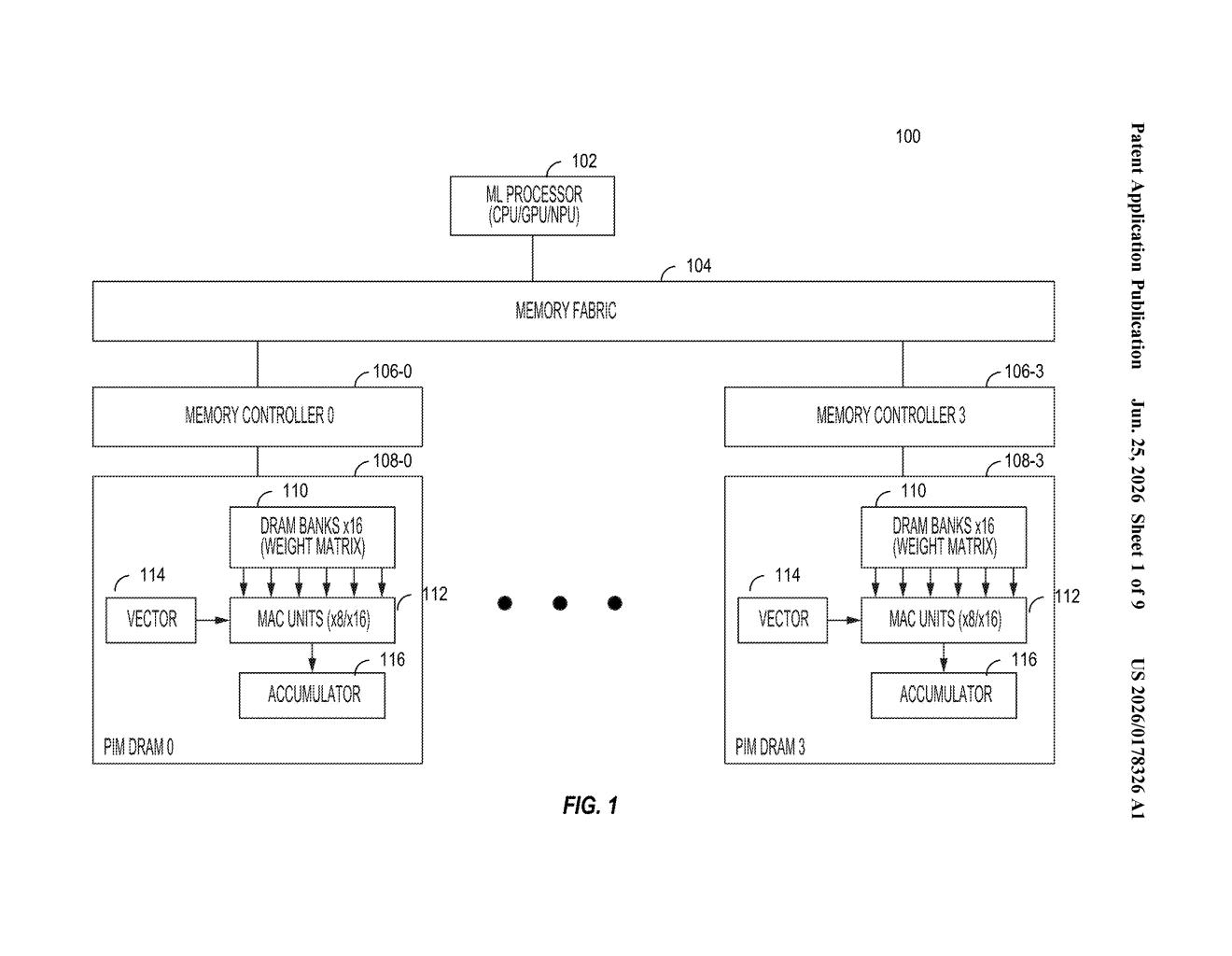
How the PIM device pipelines matrix math and memory reads
The patent covers a processing-in-memory (PIM) device optimized for block quantization, a compression technique that lets AI models store their weights (the billions of numbers that define a model's behavior) in a smaller, lower-precision format without losing too much accuracy.
Here's the core pipeline the patent describes:
- The chip splits the AI model's weight matrix (a large grid of numbers) into chunks and multiplies each chunk against an input vector (the current data being processed) directly inside the memory array.
- Results from one chunk are copied to a register (a small, fast holding area), and a read operation fetches those results while the chip is simultaneously running the next chunk's multiplication. That overlap is the key efficiency gain.
- Interspersed within the weight matrix are scaling factor columns, placed at regular intervals. These are correction numbers that convert the compressed, low-precision results back into accurate values. Dedicated multipliers inside the chip apply them in parallel, so no extra round-trip to an external processor is needed.
The design targets large language model (LLM) inference (meaning: running a trained AI model to generate answers, not training it from scratch), where matrix-vector multiplication is the dominant workload and memory bandwidth is usually the bottleneck.
What this means for on-device AI and LLM inference
On-device AI is only as good as the hardware it runs on, and right now most phones and edge devices struggle to run capable LLMs because the constant ping-pong between memory and processor eats too much time and battery. A PIM architecture that handles block quantization natively could close that gap without requiring a bigger, hotter chip.
For Qualcomm specifically, this fits squarely into its push to make Snapdragon chips the preferred platform for running AI directly on phones and laptops rather than offloading everything to the cloud. If this technique makes it into silicon, it could show up in future Snapdragon generations as a measurable improvement in how quickly your device handles AI-heavy tasks like real-time translation, on-device summarization, or AI photography processing.
This is a genuine engineering patent, not a vague concept filing. The pipelining trick of overlapping reads and computations is a concrete, implementable idea, and the block quantization focus is well-timed given how central LLM inference has become. It's infrastructure work, not a consumer feature you'll ever see named in a spec sheet, but it's the kind of thing that shows up as better battery life and faster AI responses in the next Snapdragon generation.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.