Google Patents a Mid-Generation Router That Picks the Right AI Model on the Fly
Instead of committing upfront to an expensive or cheap AI model, Google's patent describes a system that peeks inside a model mid-generation — before it even finishes — and decides whether to stick with it or hand off the request to something better.
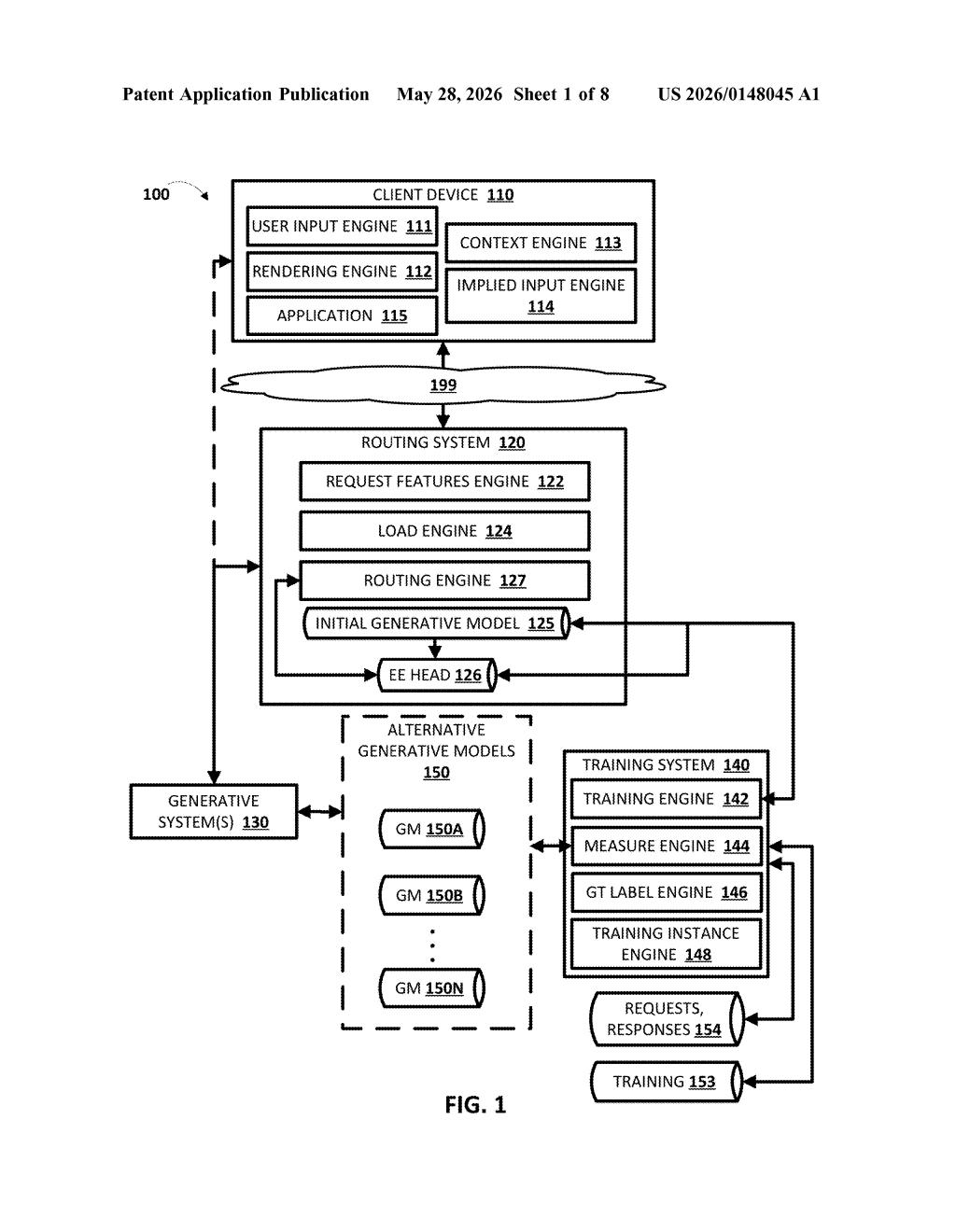
How Google's early-exit router saves AI compute
Imagine you ask a question at a help desk and the receptionist starts answering. Halfway through their response, they realize this is actually a legal question and routes you to a specialist — but they made that call before finishing their own answer, not after wasting everyone's time.
That's essentially what Google is patenting here. When you send a request to an AI system, it starts processing with a smaller, cheaper model. But before that model finishes generating its response, a lightweight "early exit head" — a tiny neural network bolted onto an intermediate layer — checks whether the job is on track or if a bigger, more capable model should take over.
The result: simple requests get fast, cheap answers, and complex ones get escalated without waiting for the first model to fail. You never notice the handoff, but the system behind the scenes is constantly making smart tradeoffs between speed and quality.
How the early exit head intercepts mid-layer signals
The patent describes a model routing system with three key components working in sequence:
- Initial generative model: The system always starts processing a request with a default model — ideally the lightest, fastest option in the fleet.
- Intermediate layer output: As the initial model processes the request, one of its hidden internal layers produces a partially-cooked representation of the request — not a final answer, but a rich signal about how the computation is going.
- Early exit (EE) head: A small, separately trained classifier reads that intermediate representation and outputs a routing decision: keep going with the current model, or escalate to an alternative model.
The key timing detail is what makes this interesting. The routing decision fires before the initial model completes its response and before any alternative model starts. This avoids the classic "run both and pick the best" waste of compute, and also avoids the latency of running the small model to completion just to decide it wasn't good enough.
The EE head is trained on historical request-response pairs with ground-truth labels (signals about which model actually produced better output), so it learns to predict model suitability from early internal activations rather than from the prompt text alone.
What this means for AI inference costs and speed
AI inference is expensive, and serving every request through a frontier-scale model is neither sustainable nor necessary. Model cascades — where cheap models handle easy queries and expensive ones handle hard ones — are a well-known cost-saving strategy, but the hard part is knowing when to escalate. Most routing systems decide at query time, before any model touches the request. Google's approach waits until the cheap model has already started processing, giving the router far richer signal about actual task difficulty.
For you as an end user, this could mean lower latency on simple requests and genuinely better answers on hard ones — without any manual setting. For Google, it's a path to serving Gemini-family models more efficiently across millions of daily requests without always defaulting to the most expensive tier.
This is a genuinely practical systems patent, not a research moonshot. Early exit mechanisms have been studied academically for years, but applying them specifically to inter-model routing — rather than just deciding when to stop decoding — is a concrete and deployable idea. The 18-inventor list suggests this came out of a serious engineering effort, and given Google's need to balance Gemini Nano, Flash, and Pro across its product surface, it's easy to see where this lands in production.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.