Google Patents a Retrieval-Augmented System for Visual Question Answering
You snap a photo of a broken appliance and type 'how do I fix this?' — Google's new patent describes a system that can search a knowledge base using both your image and your question at the same time, then pull the most relevant passage before generating an answer.
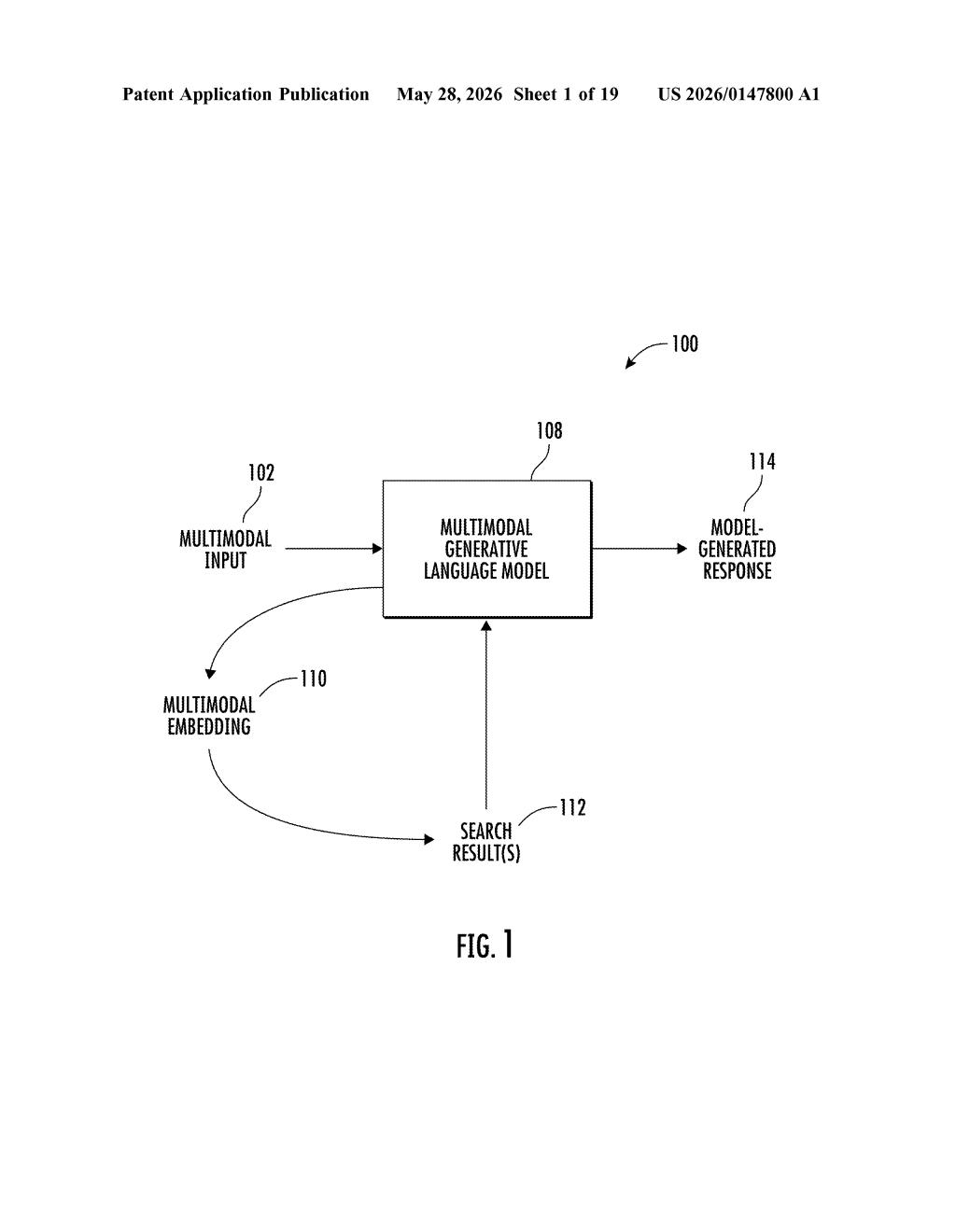
What Google's image-plus-text search pipeline actually does
Imagine pointing your phone at a product label and asking, "Is this ingredient safe for someone with a nut allergy?" Today, most AI assistants either handle the image or the text question well — rarely both together, and they typically answer from whatever they memorized during training.
Google's patent describes a system that treats your photo and your typed question as a single combined query. It converts both into a shared representation (think of it like a fingerprint that captures the meaning of both), then uses that fingerprint to search an external database for relevant content. It doesn't just grab the first result — it pinpoints the specific passage within a result that actually answers your question.
That retrieved passage then gets fed back into a language model alongside your original image and question to produce the final answer. The key benefit: the system can answer questions about things it was never explicitly trained on, because it looks things up in real time.
How the multimodal embedding drives the retrieval loop
The patent describes a retrieval-augmented generation (RAG) pipeline — a technique (now standard in enterprise AI) where a model fetches external knowledge before answering, rather than relying solely on what it learned during training — extended to work with both images and text simultaneously.
Here's the step-by-step flow:
- Multimodal input: The system accepts an input image and a text question together.
- Multimodal embedding: A decoder model encodes both the image and the text into a single vector representation — a numeric "fingerprint" that captures the combined meaning of what you're looking at and what you're asking.
- Database search: That embedding drives a similarity search against one or more external databases, returning a ranked list of content items.
- Passage selection: Rather than using an entire document, the system identifies the specific passage within the best-matching result that is most relevant to the original multimodal input.
- Answer generation: The original image, the original question, and the retrieved passage are all passed to a multimodal generative language model to produce the final response.
The patent also notes the generative model can handle orchestration — meaning it can manage search ranking and passage relevance scoring, not just final answer generation. This keeps the architecture relatively unified rather than requiring a chain of separate specialized models.
What this means for Google Lens and multimodal AI search
For products like Google Lens or Gemini's camera-based features, this approach matters because it decouples the system's knowledge from its training cutoff. A query about a newly released product, a rare medical diagram, or a niche technical manual could return accurate answers as long as the database is kept current — something a purely parametric model can't guarantee.
From a competitive standpoint, multimodal RAG is the natural next step after text-only RAG systems. Most enterprises and cloud AI providers are racing to build this exact capability. Google patenting a specific architecture — joint embedding generation, followed by passage-level retrieval, followed by grounded generation — signals where they're placing engineering bets for search-integrated AI assistants.
This is a solid, technically coherent patent, but it's describing an architecture that most serious AI labs are actively building right now. The novelty here is in the specifics — using a single decoder model to generate the multimodal embedding that drives retrieval, rather than treating image and text search as parallel pipelines — which is a meaningful engineering choice. Whether that particular design choice holds up to prior art scrutiny is a different question, but as a signal of Google's approach to grounding multimodal AI with real-time retrieval, it's worth paying attention to.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.