Adobe Patents a Graph-Based Context Retrieval System for Large Language Models
When you ask an AI a question that spans dozens of documents, most systems just do a keyword-style search and hope for the best. Adobe's new patent tries something more structured: building a graph that maps how document chunks relate to each other before the AI ever starts answering.
What Adobe's multi-document graph retrieval actually does
Imagine you've uploaded a hundred-page product brief, a support FAQ, and three policy documents into an AI assistant, then ask a question that touches on all of them. Most AI tools will grab whichever text snippets look most relevant in isolation — but they often miss the connections between chunks that live in different files.
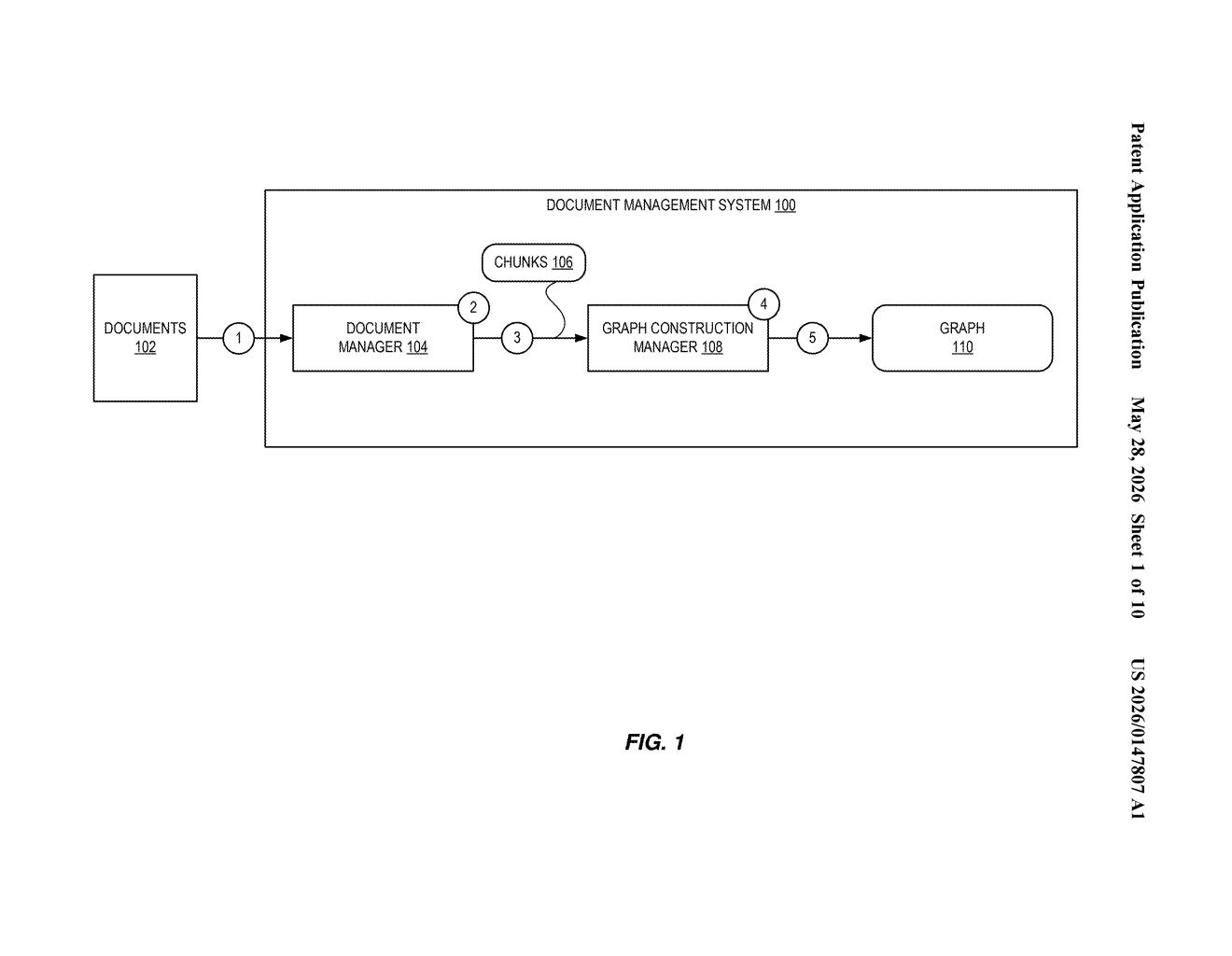
Adobe's patent describes a system that first chops all your documents into smaller chunks, then measures how similar each chunk is to every other chunk. From those similarity scores, it builds a graph — think of it like a map where each chunk is a dot, and dots that are closely related get connected by lines.
When you ask a question, the AI can use that map to navigate across related chunks, even when they come from completely different source files. The idea is that the answer you get is informed by more of the relevant context, not just the nearest-neighbor snippets a simple search would return.
How Adobe builds and queries the document similarity graph
The patent describes a pipeline centered on a multi-document graph — a data structure where each node represents a chunk of a source document, and edges between nodes encode semantic similarity (how closely related two chunks are in meaning, not just in exact wording).
The process works in stages:
- Chunking: Multiple digital documents are split into smaller, manageable pieces.
- Similarity scoring: The system computes a similarity score between every pair of document chunks — likely using vector embeddings (numeric representations of text that capture meaning).
- Graph construction: A graph is assembled where nodes are chunks and edges represent significant similarity relationships between them.
The resulting graph is then used as the retrieval backbone for a large language model (LLM). Instead of a flat vector search — which just finds the top-N most similar chunks to your query in isolation — graph-based traversal lets the system follow connected paths through the knowledge base. This is sometimes called graph RAG (Retrieval-Augmented Generation), a technique that's been gaining traction in enterprise AI research.
The patent's independent claim is deliberately broad: it covers the core method of chunking, scoring, and graph construction, leaving room for a wide range of downstream retrieval and answering implementations.
What this means for AI-powered document tools in Adobe products
Adobe's document ecosystem — Acrobat, Experience Manager, Document Cloud — puts the company in a natural position to offer AI that reasons across large, multi-file corpora. A system like this could power an "ask anything about your contract bundle"-style feature in Acrobat AI Assistant, or improve how Experience Manager surfaces content relationships for enterprise users.
For you as a user, the practical payoff is fewer "I couldn't find enough context" failures when your question requires piecing together information spread across several documents. That said, the claim as filed is quite foundational — graph-based retrieval for LLMs is an active research area with many published approaches, which could make this a tough patent to get granted in its broadest form.
Graph RAG is a legitimate research direction and Adobe has a real product use case for it — but this filing reads like a broad staking of territory rather than a disclosure of a specific novel mechanism. The independent claim essentially describes the concept of building a similarity graph from document chunks, which is well-trodden academic ground. The interesting implementation details, if any exist, are probably buried in the dependent claims or not yet disclosed.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.