Nvidia Patents a Self-Calibrating 3D Vision Model That Learns Without Labels
Labeling 3D training data is brutally expensive — every image needs a human to annotate depth, geometry, and camera angles. Nvidia's new patent describes a system that skips most of that by letting the model calibrate itself.
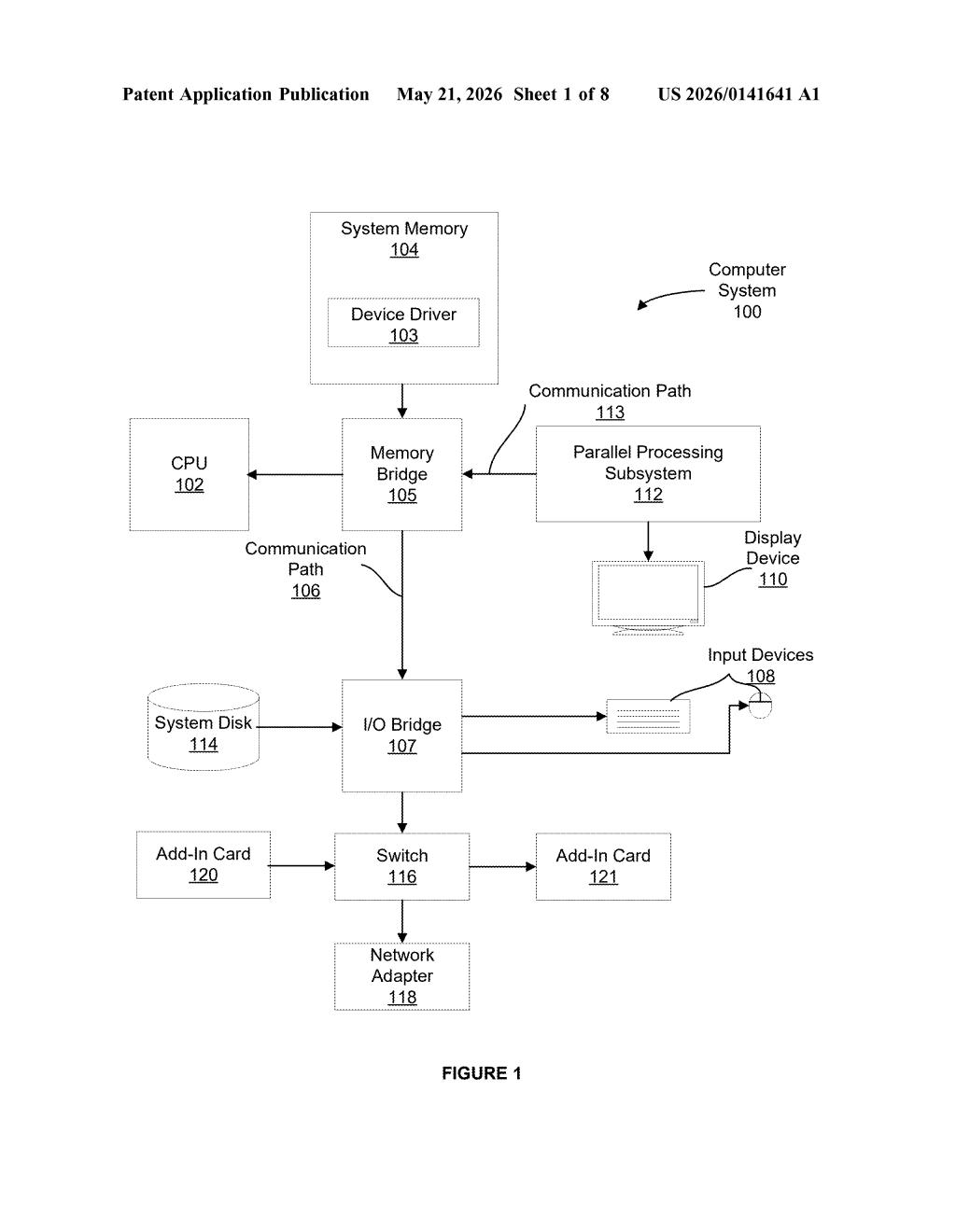
How Nvidia's 3D model teaches itself from raw images
Imagine teaching someone to read a map without ever labeling which direction is north — they'd have to figure it out from context clues in the images themselves. That's roughly the problem Nvidia is solving here. Training AI to understand 3D space normally requires enormous amounts of carefully labeled data: someone has to tell the model exactly where every point in space sits relative to the camera. That work is slow and expensive.
Nvidia's patent describes a pipeline where a pre-trained 3D vision model takes pairs of raw, unlabeled images and generates its own training labels — called pseudo-labels — by first estimating the geometry of a scene, then correcting those estimates using the camera's own intrinsic parameters (things like focal length and lens distortion). The refined geometry becomes the new ground truth.
The "low-rank" part of the name refers to a specific efficiency trick: instead of retraining the entire model from scratch on the new data, only a small slice of its internal parameters get updated. Think of it like editing a document's formatting without rewriting the whole text. The result is a model that can adapt to new environments — say, a new robot deployment location — without needing a fresh batch of expensive human-labeled images.
How point maps, confidence scores, and pseudo-labels interact
The core pipeline works in several stages. Given a batch of unlabeled images, the system selects pairs of images and runs them through a pretrained model to produce two outputs: a point map (a per-pixel estimate of where each visible surface sits in 3D space) and a confidence map (a per-pixel score of how trustworthy each 3D estimate is).
Next, the system derives the intrinsic camera parameters — essentially the mathematical fingerprint of the camera lens, covering focal length, principal point, and distortion. These parameters describe how a camera projects the real 3D world onto a flat image sensor. Getting them right is critical: if the model assumes the wrong lens geometry, all its depth estimates will be systematically wrong.
With accurate intrinsics in hand, the pipeline refines the original point maps, correcting geometric errors that stem from assuming a default or imprecise camera model. The corrected point maps and confidence scores are then combined to generate pseudo-labels — synthetic ground-truth annotations the model treats as if a human had labeled them.
Finally, the pretrained model is fine-tuned on these pseudo-labels using a low-rank adaptation strategy (similar in spirit to LoRA, the technique widely used for fine-tuning large language models). Only a small, low-dimensional subset of the model's weights are updated, keeping compute costs low while still letting the model specialize to the new scene distribution.
What self-calibration means for robotics and autonomous systems
For robotics and autonomous vehicles, deploying a 3D perception model in a new environment — a different warehouse, a new city, an unfamiliar sensor rig — currently means collecting and labeling new data, which takes weeks. A self-calibrating pipeline like this could dramatically compress that cycle: drop the model into a new context, feed it raw footage, and let it adapt on its own.
Nvidia's involvement is notable given that its Isaac robotics platform and DRIVE autonomous-vehicle stack both depend heavily on 3D scene understanding. A technique that makes geometric foundation models more portable and self-sufficient would directly reduce the data bottleneck that slows real-world robot deployments. For developers building on Nvidia hardware, this could eventually mean faster, cheaper model customization without a dedicated annotation pipeline.
This is a genuinely useful piece of infrastructure research — not flashy, but it attacks a real bottleneck in deploying 3D AI in the physical world. The combination of camera self-calibration and low-rank fine-tuning is a smart pairing: the calibration step improves pseudo-label quality, which is exactly where self-supervised approaches tend to fall apart. Worth watching as a signal of where Nvidia's robotics and autonomy stack is heading.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.