Red Hat Patents a Way to Tell Remote Devices What Data to Collect for AI Training
Training an AI model usually means hauling enormous amounts of raw data to a central server. Red Hat's new patent flips that — instead of pulling data in, it sends instructions out, telling each remote device exactly what to collect and how.
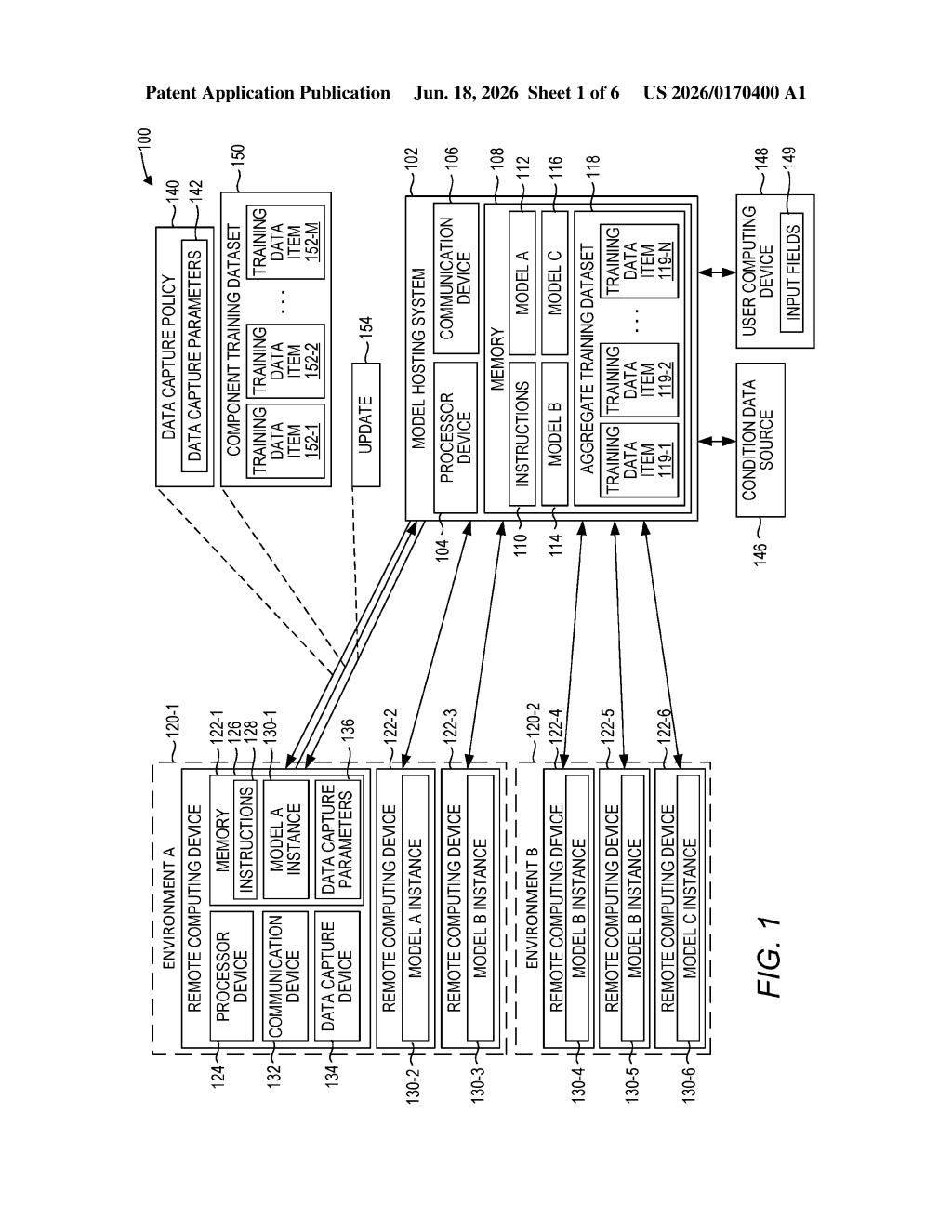
How Red Hat's distributed AI training policy actually works
Imagine you're trying to teach an AI to recognize network outages, but the clues live on thousands of servers scattered across different companies and data centers. Normally, you'd have to send all that data to one place — a privacy nightmare and a logistical headache. Red Hat's approach works differently.
Instead of collecting all the raw data upfront, the system sends each remote device a "data capture policy" — basically a specific set of instructions saying, "here's what we're trying to learn, so watch for this kind of event and save this kind of information." Each device then collects only the relevant pieces and sends that trimmed-down dataset back.
The central system pools all those mini-datasets together to train the AI model, then pushes the updated model back out to every device. Each device gets a smarter local AI without ever handing over more data than the policy asked for.
How the data capture policy travels and returns
The patent describes a policy-centric federated learning system — a flavor of distributed AI training where the training work is spread across many machines rather than done in one place.
The key innovation is the data capture policy: a structured set of rules the central server sends to each remote device before any data collection begins. Rather than capturing everything and filtering later, each device uses the policy to capture only data that is directly relevant to the training target (the specific thing the AI is being taught to recognize or predict). This keeps data volumes small and limits what leaves each device.
Once the remote devices collect their targeted datasets, they send them back. The central system then aggregates all of these component training datasets into one combined dataset and trains the model on it. The process produces a model update, which is then pushed back out to every participating device so each one's local copy of the model improves.
The cycle is designed to repeat, with the central system continuously refining what the policy asks for as the model gets better. Key components include:
- Training target identification — defining what the model needs to learn
- Data capture policy distribution — sending precise collection rules to remote devices
- Component dataset aggregation — merging results from many devices into one training batch
- Model update propagation — pushing improvements back to every device
What this means for enterprise AI and data privacy
For enterprises running AI across many locations — think hospital networks, cloud infrastructure providers, or large retail chains — sending raw operational data to a central server raises serious privacy and compliance concerns. Red Hat's policy-first design means each site only ever shares a filtered slice of data, which maps neatly onto regulations like HIPAA or GDPR that restrict where sensitive data can travel.
The approach also cuts bandwidth costs. If you run a network of edge servers, shipping terabytes of raw logs to a training cluster is expensive. Shipping only the subset the policy asked for is far cheaper. Red Hat, which sits at the center of enterprise Linux and OpenShift infrastructure, is well-positioned to embed this kind of AI training directly into the platforms its customers already run.
This is solid infrastructure work that solves a real enterprise problem — getting AI trained across many sites without creating a data-hoarding nightmare. It's not a flashy consumer play, but for Red Hat's core customers running distributed systems, it addresses exactly the friction point that slows AI adoption in regulated industries. The patent's scope is broad enough to matter strategically.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.