Qualcomm Patents a Way to Build 3D Scenes by Picking Only the Best Camera Shots
Building a 3D model from photos sounds simple — just take a bunch of pictures. But the tricky part is knowing which pictures actually matter. Qualcomm's new patent describes a system that figures that out automatically.
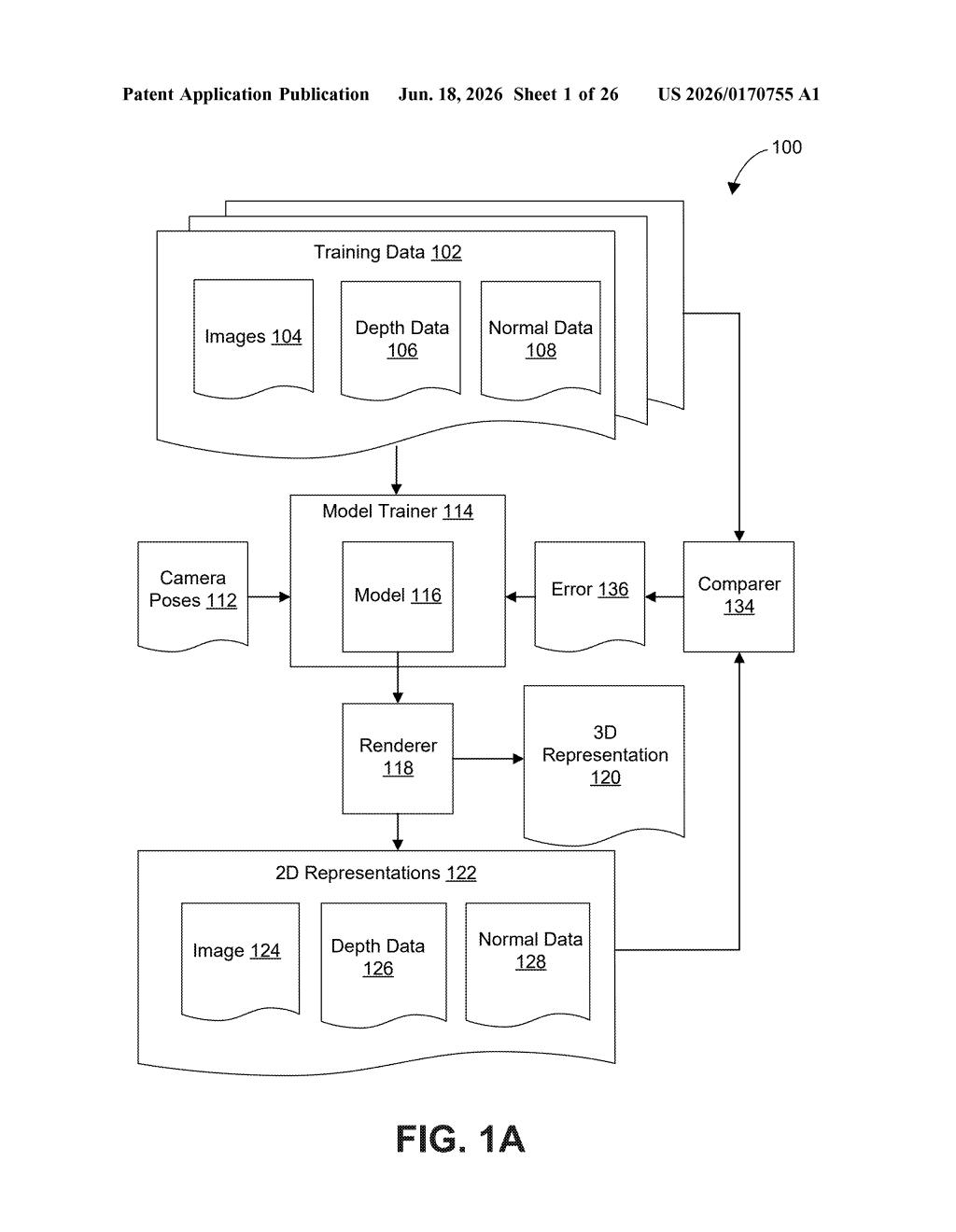
How Qualcomm's photo-selection system builds 3D models
Imagine you're trying to build a 3D model of your living room by walking around it with a camera. You could take hundreds of photos from every angle — but a lot of those shots would be redundant, and including too many bad or overlapping ones can actually make the final 3D model worse, not better.
Qualcomm's patent describes a system that solves this by being selective. It looks at where each photo was taken and what 3D points in space those camera positions correspond to, then picks only the most useful subset of images to build the final 3D scene. Think of it as trimming the fat before doing the heavy construction work.
This kind of efficiency matters a lot on mobile chips — the kind Qualcomm makes for phones and AR headsets — where you can't just throw unlimited computing power at a problem. Getting the 3D model right with fewer inputs means faster results and less battery drain.
How the system maps camera positions to 3D points
The patent describes a pipeline for building 3D representations of real-world scenes from a collection of photographs. The core innovation is in how it decides which photos to actually use.
Here's how the process works step by step:
- Collect images and camera poses — The system takes in a batch of photos, each tagged with a camera pose (a record of exactly where the camera was positioned and which direction it was pointing when the shot was taken).
- Determine 3D points — Using those camera poses, it calculates a set of 3D points in space — essentially a rough geometric map of where things are in the scene.
- Select the best subset of images — Rather than using every photo, the system compares the camera positions against those 3D points to identify which images offer the most useful coverage. Redundant or poorly positioned shots get left out.
- Generate the 3D model — Only the selected images and their corresponding poses are fed into the final 3D reconstruction step.
The underlying 3D reconstruction technique isn't specified in detail — it could be a method like Neural Radiance Fields (NeRF) or 3D Gaussian Splatting, both popular approaches for turning photos into navigable 3D scenes. What the patent specifically claims is the smarter input-selection layer sitting in front of that process.
What this means for AR, mapping, and on-device 3D
Qualcomm's chips power a huge share of Android phones and are central to many AR headsets, including the Meta Quest line. Any technique that makes 3D scene reconstruction faster or less compute-heavy is directly relevant to those devices — where battery life and processing speed are real constraints. If you can get a good 3D model with half the input images, that's a meaningful win on a mobile chip.
More broadly, this kind of approach feeds into use cases like spatial computing, indoor mapping, and AR applications that need to understand a physical space in real time. As those applications move from experimental to everyday, efficient 3D reconstruction becomes less of a research problem and more of a product requirement. Qualcomm positioning itself in this space — at the hardware-software intersection — is a logical play.
This is solid, unglamorous infrastructure work. Qualcomm isn't inventing a new way to make 3D models — it's patenting a smarter way to feed data into the models that already exist. That's actually the kind of incremental optimization that ends up shipping in real products, especially on constrained mobile hardware where every computation has a cost.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.