Tesla Patents a Simulated-Data Training Loop for Vision-Only Vehicles
Tesla's self-driving system relies entirely on cameras — no radar, no lidar. This patent describes how Tesla plans to make that vision-only approach more capable by feeding it a diet of simulated images alongside real-world data.
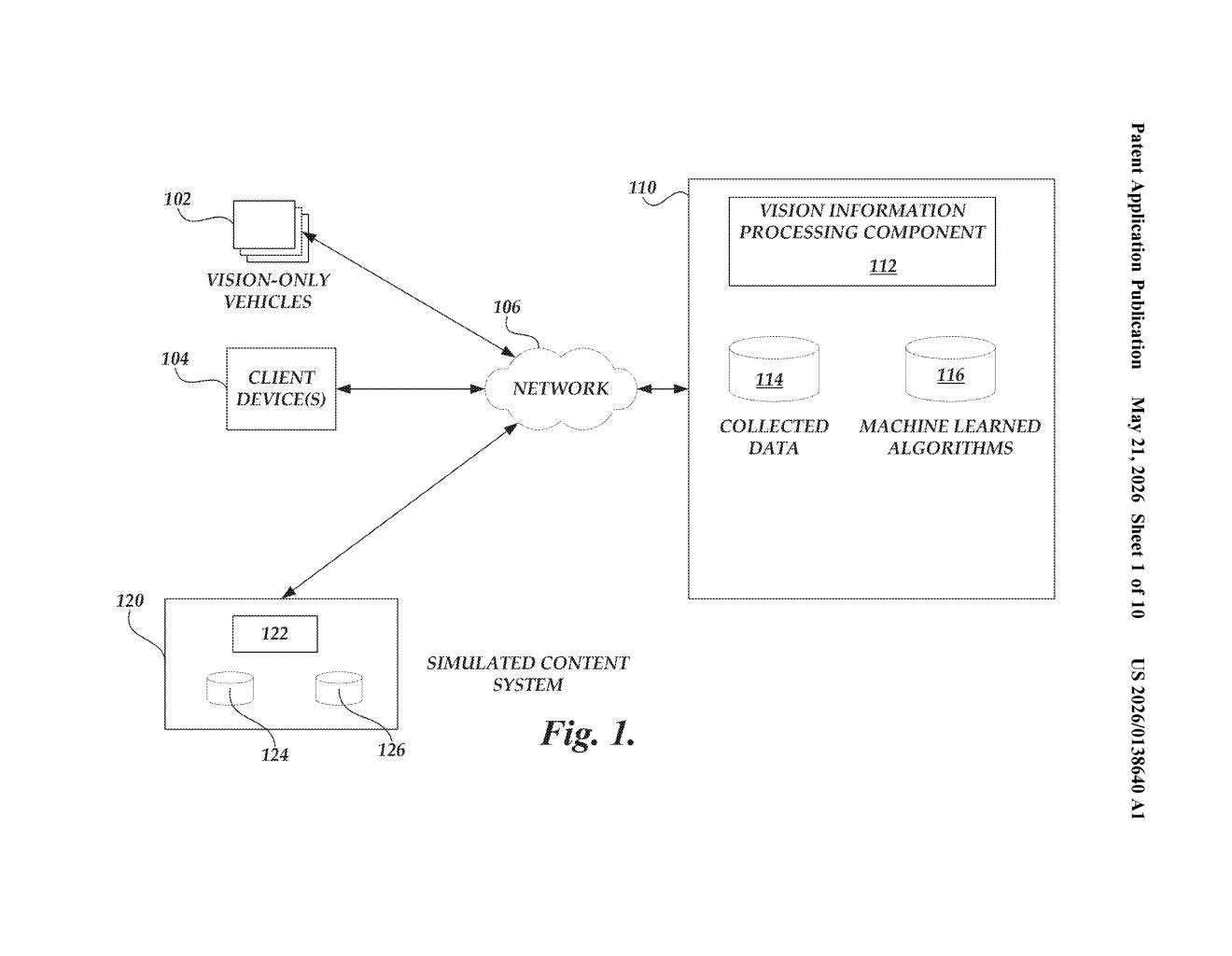
What Tesla's sim-to-real vision training actually does
Imagine trying to teach a new driver how to handle a blizzard, a flooded road, or a pedestrian running a red light — but you can't just wait for those situations to happen naturally. You'd want a simulator. That's the core idea here.
Tesla's cars use cameras alone to understand the world around them — there's no radar backup. To train the software that interprets all that camera footage, Tesla needs enormous amounts of labeled data (images where every car, sign, and lane marking is tagged). This patent describes a system that mixes real camera footage from Tesla's fleet with computer-generated images to build richer training sets faster.
The system doesn't just throw fake images into the mix randomly. It uses a priority-ordered approach to figure out which kinds of simulated content are most useful — then indexes and tags that content so the machine learning model can learn from it in a structured way. Think of it as a curriculum for the AI, not a random firehose.
How Tesla blends real labels with simulated content
The patent describes a pipeline with a few key stages:
- Real-world data collection: Cameras on Tesla vehicles capture footage along with ground truth labels — structured tags identifying objects like pedestrians, traffic lights, lane lines, and other vehicles.
- Content model generation: A subset of those labels is processed to build a content model — essentially a structured description of what kinds of scenarios and objects are present in the data, ranked by an ordered priority of content model attributes.
- Simulated content synthesis: A simulation system generates additional visual images and matching labels to fill gaps — edge cases, rare weather conditions, unusual road geometries, or scenarios that are hard to capture in the real world at scale.
- Index-based association: The simulated content is tagged with index data tied to the content model, so the machine learning model can be configured with awareness of both real and synthetic inputs.
The trained model then takes in new, unseen camera footage and classifies objects and agents in the environment. The architecture is designed specifically for vision-only vehicles — systems that have no sensor modalities beyond cameras to fall back on.
Why sim-based training matters for radar-free Autopilot
Tesla made a high-profile bet years ago by removing radar from its vehicles and doubling down on cameras. That bet only pays off if the vision model is exceptionally robust across a huge range of conditions — many of which are rare in real-world driving data. Simulation is the practical answer to that data scarcity problem, and this patent formalizes how Tesla structures that process.
For you as a Tesla owner or prospective buyer, this kind of infrastructure work is what makes over-the-air software improvements possible. Better-trained models ship as updates. The more structured and prioritized the training pipeline is, the faster Tesla can improve Autopilot and Full Self-Driving without waiting for its fleet to organically encounter every dangerous scenario.
This is solid, unsexy infrastructure work — the kind of thing that doesn't generate headlines but directly determines how good Tesla's Autopilot software actually gets. The prioritized content model approach is a real engineering choice, not just 'add more simulation,' and that specificity makes this patent worth noting. It's a window into how Tesla is systematically attacking the data problem that all vision-only autonomy systems face.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.