Waymo Patents Contrastive Learning to Align Self-Driving Sensor Data with Language
Waymo's latest patent trains its autonomous vehicle sensors by teaching them to agree — not just with each other, but with natural language descriptions of what they're seeing. It's a clever way to squeeze more meaning out of raw sensor data.
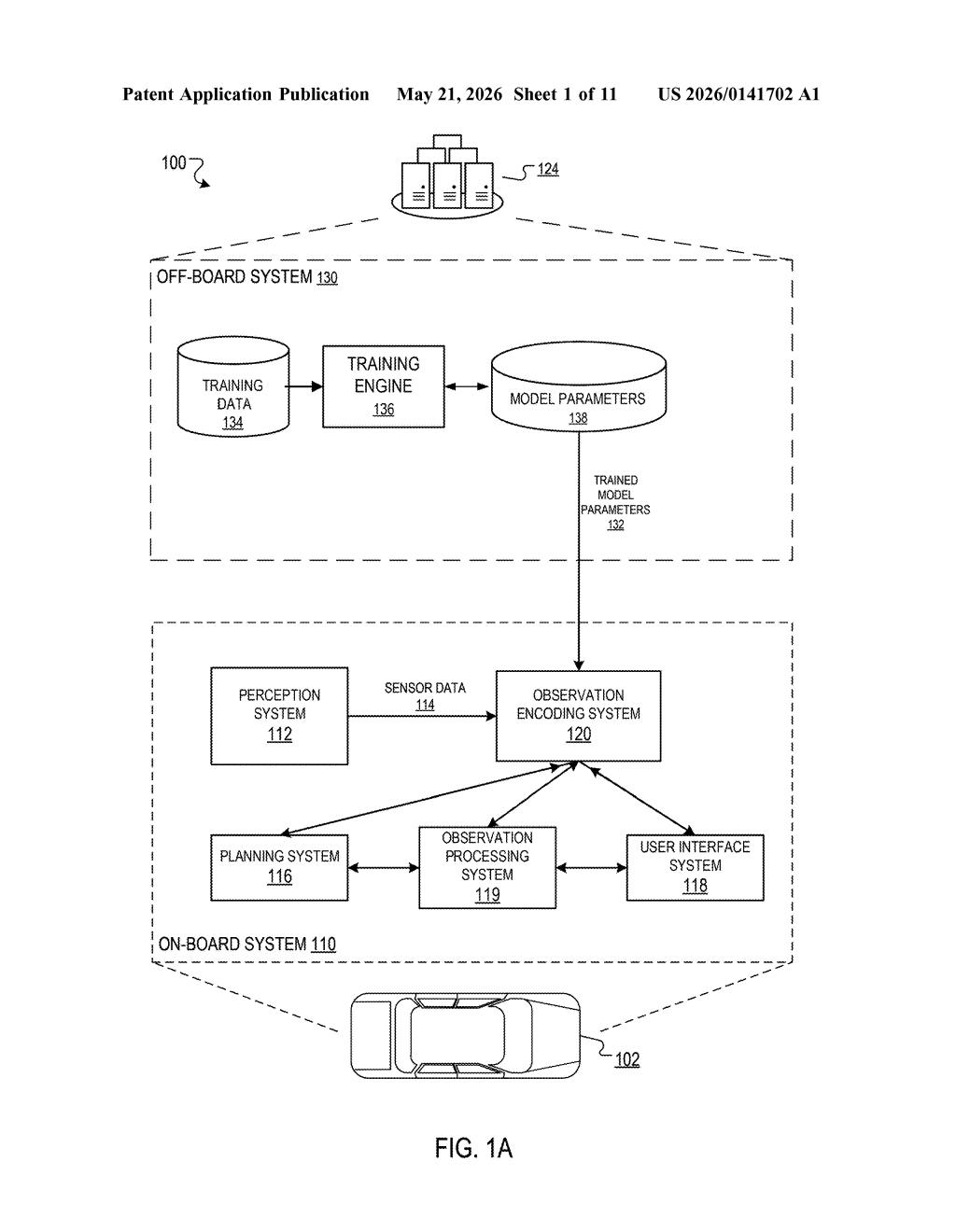
How Waymo teaches sensors to agree with each other
Imagine you're learning to recognize a stop sign. You could study photos of stop signs, or you could read the description 'a red octagonal sign that means stop.' Waymo's patent does both at once — it trains its self-driving car's sensors by comparing what a sensor sees with a plain-English description of that same scene.
The idea is that if a camera, lidar, or radar sensor produces an embedding (a compact numerical summary of what it detected), and a text description of the same moment produces a similar embedding, the two are probably describing the same reality. Waymo uses this agreement — or disagreement — as a training signal to make each sensor's encoder more accurate over time.
The result is a sensor-processing system that's been tuned not just by labeled driving data, but by a richer, language-grounded understanding of what's happening in the world around the car. Contrastive learning is the underlying technique — widely used in AI image models — and Waymo is applying it directly to the messy, multi-modal sensor stack of a real autonomous vehicle.
How the modality alignment loss trains the encoder
The patent describes a training framework for what Waymo calls an observation encoding system. Here's the core loop:
- A sensor (say, a lidar array or camera) captures a driving scene — this is the first sensor modality.
- A second modality — for example, a camera feed or other sensor — generates observations that are converted into text descriptions using a language model or captioning system.
- Both the raw sensor observation and the text description are encoded into embeddings (dense numerical vectors that represent meaning in high-dimensional space).
- A modality alignment loss function measures how well these two sets of embeddings agree. If the lidar says 'pedestrian crossing ahead' and the text description says the same thing, the loss is low. If they disagree, the encoder gets penalized and adjusts.
This is contrastive learning — a technique popularized by models like CLIP (OpenAI's image-text model) where you train an encoder by pulling matching pairs together in embedding space and pushing non-matching pairs apart.
Once the encoder is trained this way, it's used at inference time: the vehicle receives new sensor data, the encoder produces an embedding, and a separate prediction neural network uses that embedding to generate driving predictions — things like 'is that pedestrian about to step into the road?' The text descriptions are only needed during training; at deployment, the car doesn't need language at all.
What this means for multi-sensor autonomous driving
Self-driving cars drown in sensor data — lidar point clouds, radar returns, camera frames, all arriving simultaneously. Getting each of those modalities to produce encodings that are semantically consistent (meaning they represent the world in a compatible, comparable way) is one of the harder unsolved problems in AV perception. Using language as a common grounding signal is an elegant side-step around the need for perfectly labeled multi-sensor datasets.
For Waymo, this could mean faster iteration on sensor fusion models, better generalization to novel scenarios, and a path toward using foundation-model-style pretraining for AV perception — all without needing a human to hand-label every edge case the car encounters on the road.
This is a genuinely interesting patent because it transplants a technique that worked spectacularly in vision-language AI (CLIP-style contrastive learning) into the tougher, safety-critical domain of autonomous vehicle sensors. The language-grounding trick is smart: natural language is a cheap, scalable source of supervision that doesn't require expensive lidar-level annotation. Whether Waymo can make this work robustly across all sensor modalities at production scale is the real question — but the direction is clearly right.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.