Nvidia Patents an AI Pipeline That Labels Its Own Self-Driving Training Data
Training a self-driving AI requires millions of labeled sensor frames — and labeling them by hand is slow and expensive. Nvidia's new patent describes a system where the AI essentially grades its own homework, flagging only the tricky cases for human reviewers.
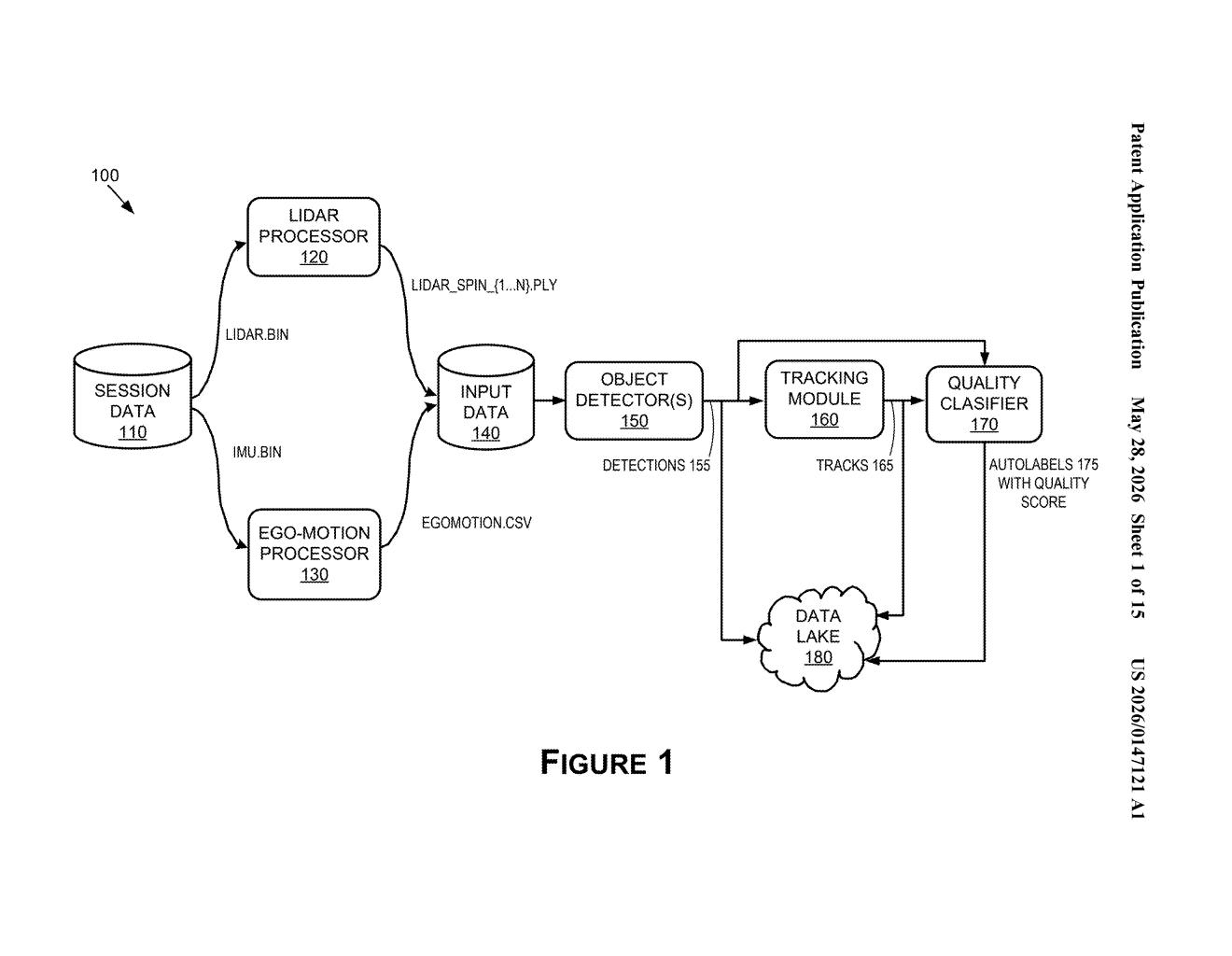
How Nvidia's self-driving cars label their own sensor data
Imagine trying to teach a self-driving car to recognize other vehicles, pedestrians, and cyclists. To do that, you need to show it thousands of examples where every moving object in a sensor scan has been carefully identified and tagged. That tagging process — called annotation — is traditionally done by human workers staring at raw sensor data for hours.
Nvidia's patent describes a way to automate most of that work. Laser sensor (LiDAR) data collected by test vehicles gets fed into a neural network, which detects moving objects, tracks them across multiple frames, estimates how fast they're moving, and assigns each detection a quality score. High-confidence detections get labeled automatically and skipped during the human review queue.
The result: human annotators only spend time on the hard cases — objects that were partially hidden, moving erratically, or detected with low confidence. The system promises to speed up the pipeline for building the massive training datasets that self-driving AI depends on.
How the transformer network scores and tracks LiDAR objects
The system starts with raw LiDAR point-cloud frames — essentially 3D snapshots made of millions of laser range measurements — captured by data-collection vehicles out in the real world.
Those frames are processed by a transformer neural network (the same architecture behind large language models, but applied to spatial sensor data). The network detects dynamic objects — cars, pedestrians, cyclists, and other designated classes — and generates initial detection outputs called detections.
A separate tracking module then stitches detections across time into continuous object tracks (sometimes called tracklines), while also estimating velocity and handling occlusions (moments when one object briefly hides behind another). Track geometry and per-detection confidence are used to refine the tracks.
Finally, a quality classifier scores each auto-label. Labels that clear a threshold score are exported directly as ground truth — the authoritative training signal — and are flagged to skip human review. Labels that score below the threshold are queued for human annotators. The claim language specifically covers exporting this scored ground-truth representation for downstream use in training perception networks.
What this means for autonomous vehicle AI training at scale
Building perception models for autonomous vehicles is a data-hungry process, and annotation bottlenecks are a real constraint on how fast teams can iterate. By letting a neural network pre-validate its own outputs, Nvidia's approach could dramatically compress the time between a data-collection drive and a usable training batch — which matters a lot when you're trying to cover edge cases like night driving, construction zones, or unusual pedestrian behavior.
This also signals where Nvidia sees its autonomous vehicle platform business going: not just selling the chips that run inference in the car, but owning the full pipeline — data collection, auto-labeling, model training, and deployment — that keeps those models improving over time.
This is genuinely useful infrastructure work. Auto-labeling with quality gating is a well-known technique in ML, but the combination of transformer-based LiDAR detection, multi-frame tracking with occlusion handling, and a dedicated quality classifier in one unified pipeline is a real engineering investment. It's less about a single clever idea and more about Nvidia locking in the end-to-end data flywheel for its DRIVE platform.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.