Google Patents an AI Building Block That Fades Instead of Snapping
Every neural network needs activation functions to decide which signals get passed forward — and the most popular one, ReLU, has a well-known rough edge that can cause training headaches. Google's new patent describes a family of smoother replacements that behave like ReLU without that rough edge.
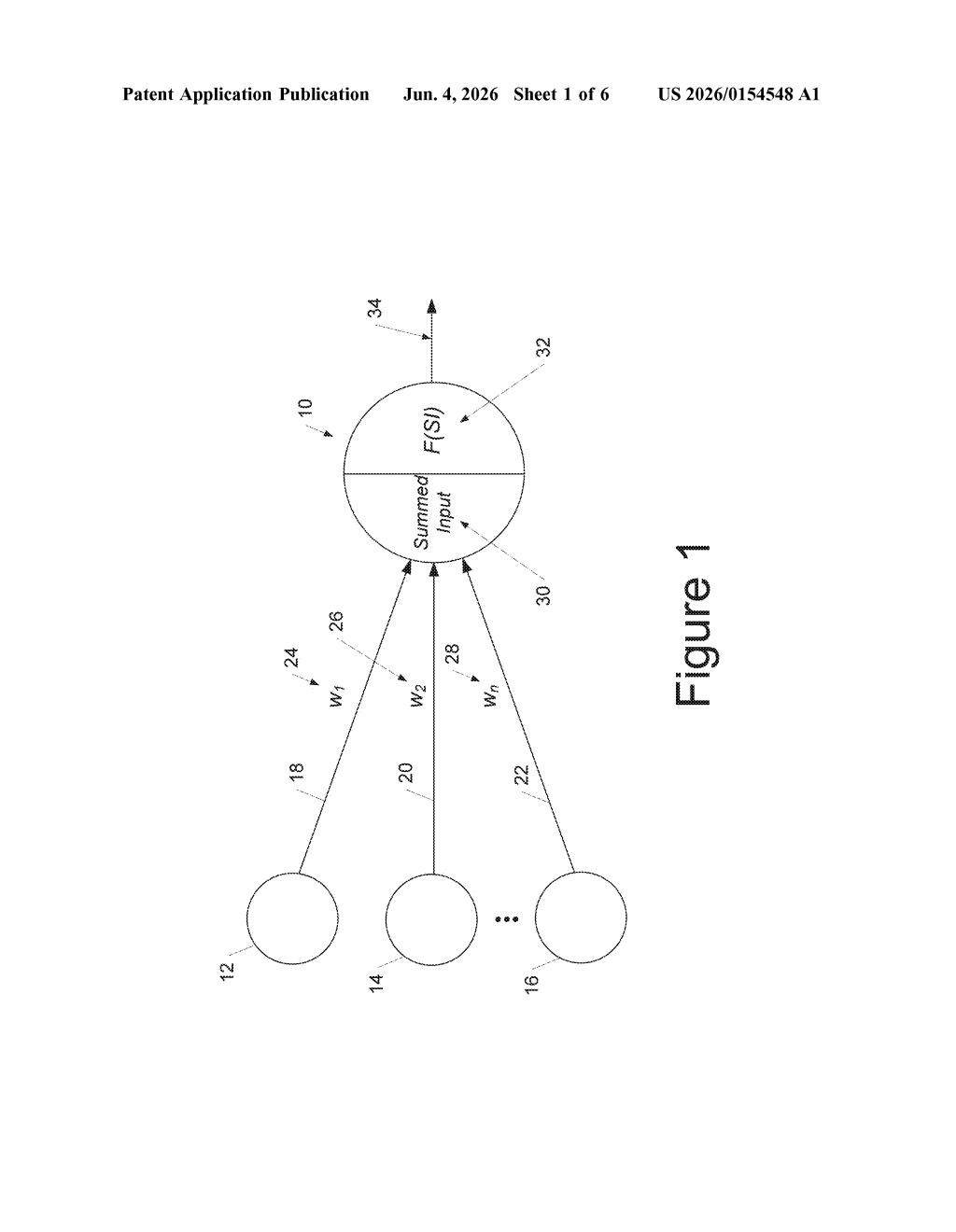
What Google's smooth activation function actually changes
Imagine a dimmer switch versus a light switch. A standard light switch (ReLU) snaps hard between off and on — which is useful, but that abrupt snap can cause problems when you're trying to fine-tune a system. Google's patent describes something closer to a dimmer: an activation function that transitions smoothly between its "off" and "on" states while still acting like a light switch in all the ways that matter for accuracy.
Activation functions are tiny math operations baked into every layer of a neural network. They decide whether a neuron's signal gets passed along and how strongly. The dominant one, called ReLU (Rectified Linear Unit), is fast and accurate but has a kink at zero — a sharp corner where the math gets discontinuous — which can make training results vary slightly depending on hardware or floating-point rounding.
Google's approach builds the activation function from multiple smooth curve segments that connect seamlessly at their joints, with no abrupt corners. The result keeps ReLU's defining behaviors — a flat "stop" zone and a straight "pass" zone — but with gradients that flow continuously through the whole curve, making training more predictable and reproducible across different systems.
How the piecewise segments stay continuous at every join
The patent describes a piecewise activation function — a curve assembled from two or more mathematical segments that join at "transition points." The key innovation is the constraint: not only must the segments themselves be continuous at each join (no jumps), but their gradients (the slopes used during backpropagation, the process by which neural networks learn) must also be continuous there. That's the "smooth" part — no kinks anywhere.
Standard ReLU is famously not smooth: it has a hard corner at zero where its gradient jumps from 0 to 1 instantaneously. This discontinuity is mathematically simple and computationally cheap, but it can cause reproducibility issues — small differences in hardware rounding can push a value onto different sides of that corner, producing slightly different results across GPUs or between training runs.
Google's system selects activation function parameters (the constants that shape each segment) from a constrained solution set — essentially a family of valid configurations — so the smoothness and continuity conditions are guaranteed by construction. The patent also covers a leaky variant (analogous to Leaky ReLU, which allows a small gradient in the stop zone rather than zero) and variants with different constant gradients in the pass region.
The practical pitch is that these functions can slot in where ReLU currently lives — matching its accuracy characteristics — while eliminating the gradient discontinuity that makes bit-exact reproducibility hard to achieve.
What this means for reproducibility in production AI models
Reproducibility is a real, quiet pain point in production machine learning. If rerunning the same training job on different hardware or with slightly different floating-point behavior gives you different model weights, debugging and certifying models becomes harder. A smooth activation function that otherwise behaves like ReLU could reduce that noise without forcing teams to retrain from scratch or sacrifice accuracy.
For Google's own infrastructure — TPU clusters, Vertex AI, Gemini model training — even small improvements in training determinism at scale could matter. This is infrastructure-level plumbing, not a flashy end-user feature, but that's exactly the kind of thing that quietly improves reliability across millions of model training runs.
This is a narrow, technically solid contribution to a real problem — gradient discontinuities in ReLU genuinely do affect reproducibility — but it's incremental work in a crowded space where GELU, Swish, and Mish already offer smoother alternatives. The value here is the formal parametric framework and the explicit solution-set construction, not a brand-new idea. Worth watching if you care about deterministic training at scale; easy to skip if you don't.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.