Samsung Patents a Dual-Track Image Input System for On-Device AI Models
Most AI vision systems make a choice: send raw image detail or compressed tokens to the model. Samsung's new patent says you don't have to pick — send both at once.
What Samsung's dual image-input AI actually does
Imagine you're asking an AI assistant on your phone a question about a photo you just took. Under the hood, the AI needs to "read" that image, but there's a tricky trade-off: do you give it a rich, detailed representation of every pixel (which is heavy and slow), or a compact summary that's fast but might miss details?
Samsung's patent describes a system that does both at the same time. It uses one component to extract detailed visual features from your image, and a second component to compress those features into a leaner set of "tokens" — bite-sized chunks an AI language model can process more easily. Then it hands all of that — the full features, the compact tokens, and your text prompt — to the AI model together.
The idea is that the model gets the best of both worlds: the precision of detailed image data and the efficiency of a compact representation. Think of it like giving someone both a high-resolution photo and a well-written caption — they can cross-reference both to give you a better answer.
How the image encoder and tokenizer feed the foundation model
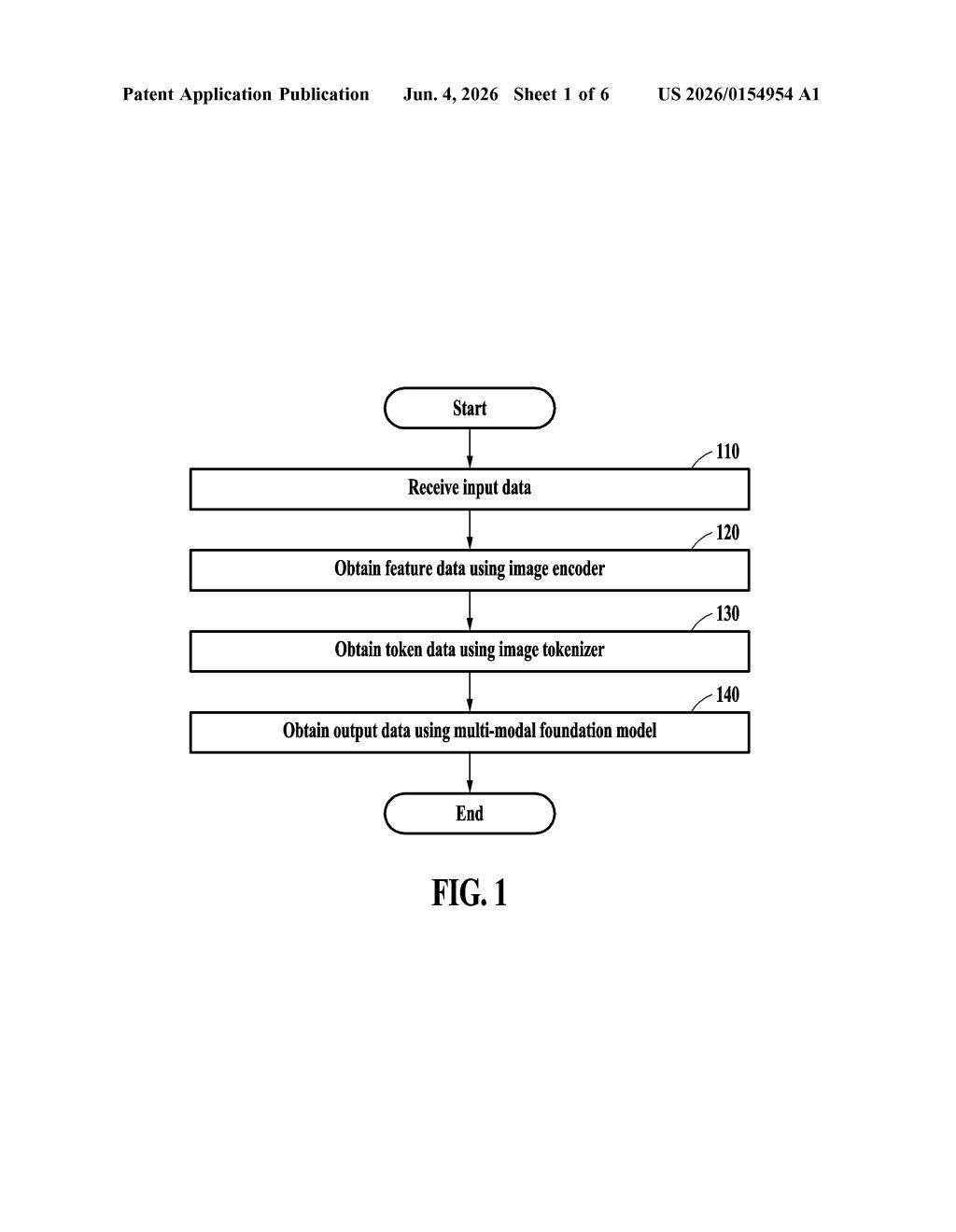
The patent describes a multi-modal foundation model (MMFM) pipeline with a distinctly dual-path image processing setup.
When you feed the system an image plus a text prompt (say, "What's wrong with this circuit board?"), here's what happens:
- An image encoder processes the raw input image and produces image feature data — a rich, high-dimensional representation of visual content, similar to what a vision transformer or CNN backbone produces.
- An image tokenizer then takes those features and converts them into image token data — a discrete, compressed sequence that looks more like the word tokens a language model expects.
- The MMFM then receives all three inputs simultaneously: the original text prompt, the dense image features, and the compressed image tokens.
The key architectural claim is that the model ingests both the feature representation and the tokenized version of the same image — not one or the other. This redundancy is intentional: the model can lean on the rich spatial detail from the encoder when precision matters, and use the token stream for efficient language-style reasoning.
This mirrors ongoing research in the broader AI community around hybrid visual representations, where models like LLaVA or Flamingo have explored how best to "talk" image data to a language backbone. Samsung's framing here emphasizes the combined feed as a structural feature, not a fallback.
What this means for Samsung's on-device AI ambitions
Samsung has been pushing hard on on-device AI — the Galaxy S series already ships with Galaxy AI features, and the company has a direct interest in running capable vision-language models without leaning entirely on cloud compute. A pipeline that gives the model both a detailed and a compressed view of an image could help squeeze more accuracy out of smaller, more efficient on-device models, since the model has more signal to work with.
For you as a user, this could eventually mean an AI assistant that handles photo-based queries — "What's this plant?", "Is this receipt readable?", "Fix the color in this image" — with noticeably better accuracy, without draining your battery on a cloud round-trip. That's a real quality-of-life improvement if Samsung can make the pipeline efficient enough to run on a phone.
This is a solid, well-scoped architectural patent rather than a moonshot claim. The dual-path image input concept is genuinely interesting as an engineering trade-off — most deployed systems pick one representation style. Whether this specific combination offers meaningful gains over well-tuned single-path systems is an empirical question, but it's the kind of incremental systems work that quietly ends up shipping in flagship devices.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.