Nvidia Patents a Dual-AI System for Dynamic Cloud Resource Pool Sizing
Running a cloud service means constantly guessing how many servers you'll need at 2 PM on a Tuesday. Nvidia's new patent uses two separate AI models to stop guessing and start predicting — one for how often requests arrive, another for how long each session actually lasts.
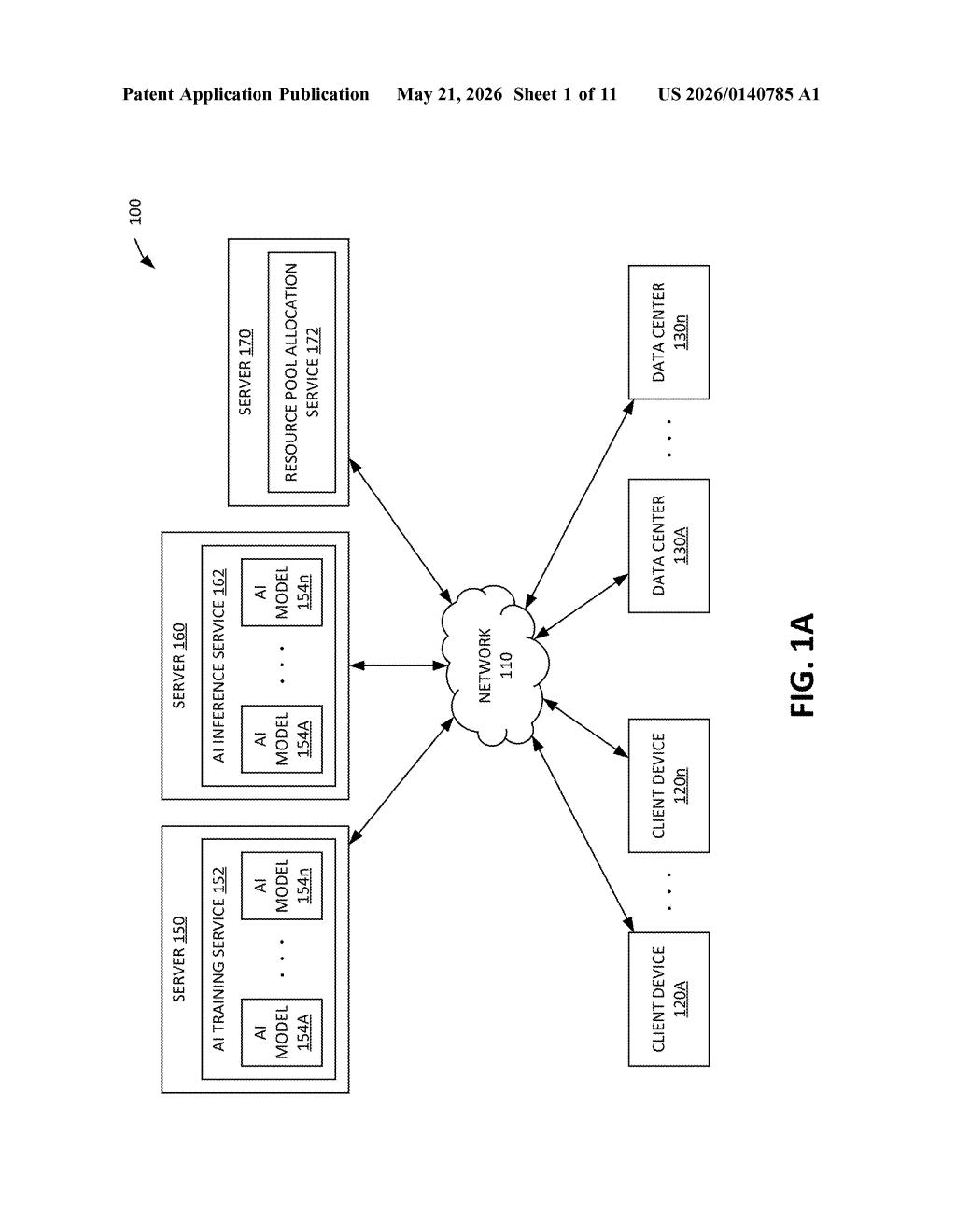
How Nvidia's two-model approach sizes cloud pools
Imagine you're running a video streaming service. At any moment, thousands of people are starting and stopping sessions — some watch for two minutes, others for two hours. If you provision too few servers, things crash. Too many, and you're burning money on idle hardware. This is the core tension of cloud resource management.
Nvidia's patent tackles this by running two AI models in tandem. The first predicts the rate at which new requests are coming in during a given time window. The second predicts how long those sessions will last. Together, they estimate the realistic peak number of sessions that could be active at the same time.
Once you have that peak estimate, the system dynamically allocates exactly the right number of computational resources to that pool — not a flat over-provision, and not an optimistic under-provision. It's essentially a continuously recalibrating headcount forecast for your server farm.
How the two AI models estimate peak concurrent sessions
The patent describes a resource pool allocation service that sits above one or more data centers and manages multiple computational resource pools simultaneously. Each pool can represent a different workload, tenant, or service.
For any given pool, the system runs two distinct AI models:
- Request rate model: produces a distribution (not just a single number) of how many new sessions are expected to arrive per unit time during the target window — think of it like a probability histogram of arrival rates.
- Session duration model: produces a distribution of how long those sessions will persist — again, a range with probabilities, not a fixed assumption.
The system then combines these two distributions to compute an estimate of maximum concurrent sessions (the peak overlap of active sessions). This is essentially a queuing-theory calculation — how many sessions started before others ended — done probabilistically using AI-generated inputs rather than static historical averages.
Finally, the number of computational resources (CPUs, GPUs, memory allocations) assigned to that pool for the time period is set based on that peak estimate. The process repeats across time periods, keeping allocations continuously tuned to predicted demand.
What this means for cloud infrastructure efficiency
Cloud over-provisioning is a massive and largely invisible cost. Data centers routinely sit at 20–40% utilization because operators pad capacity to handle worst-case spikes. A system that accurately forecasts peak concurrent load — rather than defaulting to worst-case assumptions — could meaningfully reduce wasted compute and lower operational costs at scale.
For Nvidia specifically, this sits at an interesting intersection: the company sells the GPUs that fill these data centers, but it also runs cloud AI inference services. A patent like this suggests Nvidia is thinking seriously about the orchestration layer of AI cloud infrastructure, not just the silicon underneath it. Better resource sizing directly improves the economics of GPU-as-a-service offerings.
This is solid infrastructure work — not flashy, but it addresses a real and expensive problem that every large cloud operator faces. The two-model approach (separating arrival rate from session duration) is a genuinely sensible decomposition of the problem, since the two variables have very different statistical behaviors. Whether this ends up in Nvidia's own cloud services or gets licensed as part of a broader platform play, it's worth tracking as Nvidia continues building up the software stack around its hardware.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.