IBM Patents a Probability-Map Approach to Finding Objects in Images
IBM is patenting a way to find objects in images without training a massive model from scratch — instead, you just show the system a few marked-up examples of what you're looking for, and it builds a probabilistic map to hunt for matches in new images.
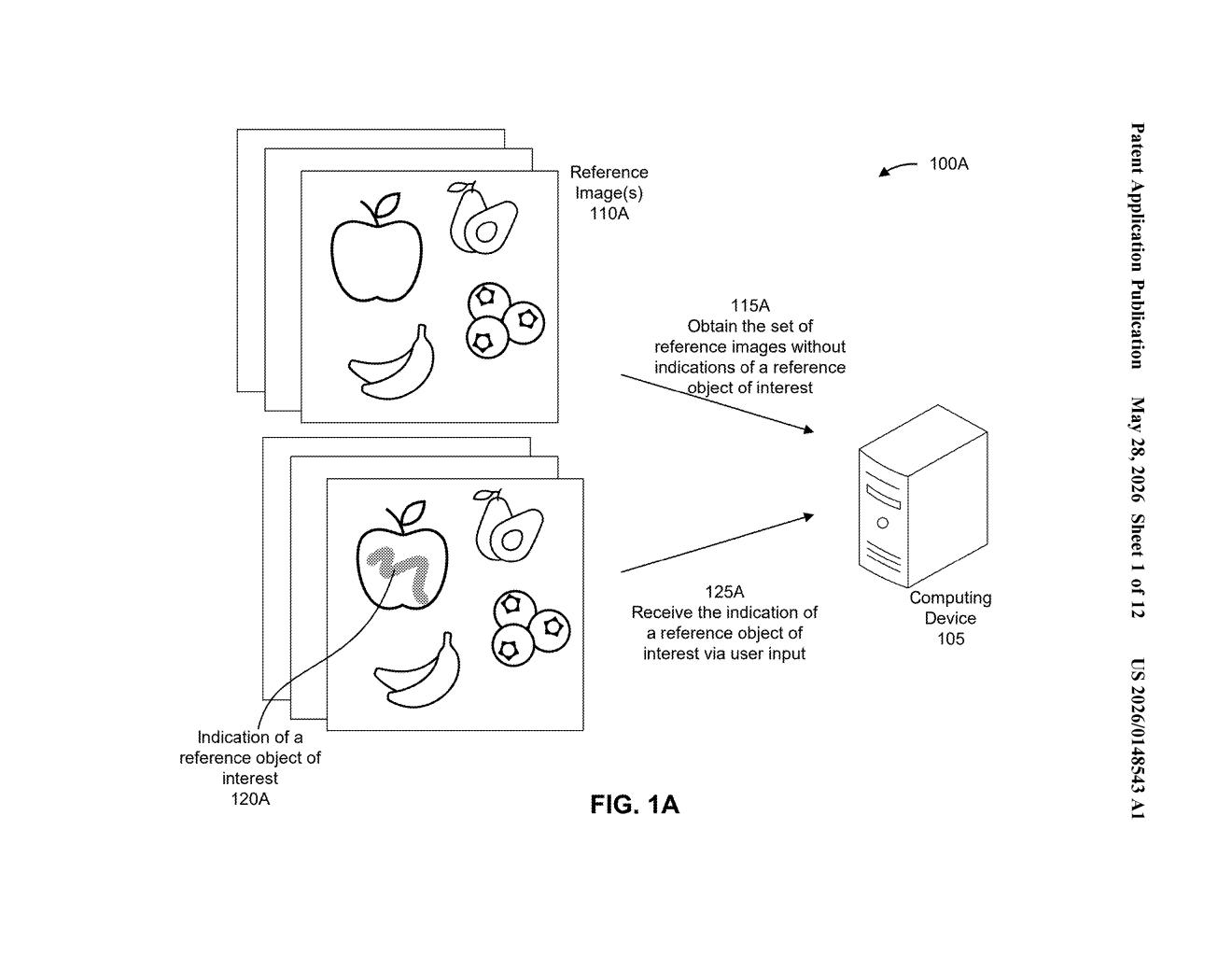
What IBM's reference-image object finder actually does
Imagine you're a quality-control engineer at a factory and you need a computer to spot a specific defective component on an assembly line. Normally, teaching a vision system to recognize that defect requires hundreds or thousands of labeled photos and a lengthy training run. IBM's patent describes a different approach: you hand the system a small set of reference images where you've already circled or marked the object you care about, and it figures out the rest.
The system takes those marked-up examples, computes how closely patches of a new target image match what you showed it, and assembles those scores into a probability map — essentially a heat map that says "this region is probably the thing you're looking for."
The practical upside is flexibility. You don't need to retrain a model every time you want to find a new kind of object. You just swap in new reference images and point-and-click what matters.
How IBM builds a probability map from matching scores
The patent describes a three-stage pipeline. First, a user provides one or more reference images, each annotated with an indication (likely a bounding box or mask) of the reference object of interest — the thing the system should learn to recognize.
Second, the system generates matching scores by comparing features extracted from the reference object against regions of a new target image. These scores reflect how well each region of the target resembles the reference object. The scores are then assembled into a probability map — a spatial grid where higher values indicate regions more likely to contain the object of interest.
Third, the system uses that probability map to identify (localize or detect) the object within the target image — essentially thresholding or peak-finding on the map to pinpoint matches.
- Reference annotation: user marks the object in a few seed images
- Feature matching: scores quantify similarity between reference and target regions
- Probability map: spatial confidence surface over the target image
- Object identification: localization derived from map peaks
The probabilistic framing is notable: rather than a hard binary "object here / not here" detector, the output is a continuous confidence surface, which makes it easier to handle partial matches, occlusion, or scale variation.
What this means for few-shot visual search systems
This kind of few-shot visual search — where you describe what you want by example rather than by training data — is genuinely useful in enterprise settings like manufacturing inspection, document analysis, and medical imaging, where labeled datasets are expensive or impossible to build at scale. IBM's Watson and watsonx product lines already target exactly these industrial and regulated verticals.
For everyday users, the broader pattern here is a shift toward interactive, example-driven AI rather than pre-trained classifiers locked to a fixed set of categories. If IBM can make this robust and fast enough, it becomes a building block for drag-and-drop visual automation — the kind of thing that could slot into low-code enterprise tools without requiring a data science team.
This is solid, practical computer vision work aimed squarely at IBM's enterprise customer base — not a flashy consumer feature. The probabilistic framing is a sensible design choice, and the few-shot setup has real value in domains like industrial inspection where labeled data is scarce. It won't make headlines outside CV circles, but it's the kind of patent that quietly shows up in a product two years later.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.