Google Patents an On-Device AI That Ranks What Context Actually Matters
When you ask your phone's AI assistant something, it drowns in background noise — your location, your calendar, your recent apps. Google's new patent describes a way for the AI to figure out which of that context actually matters before it answers.
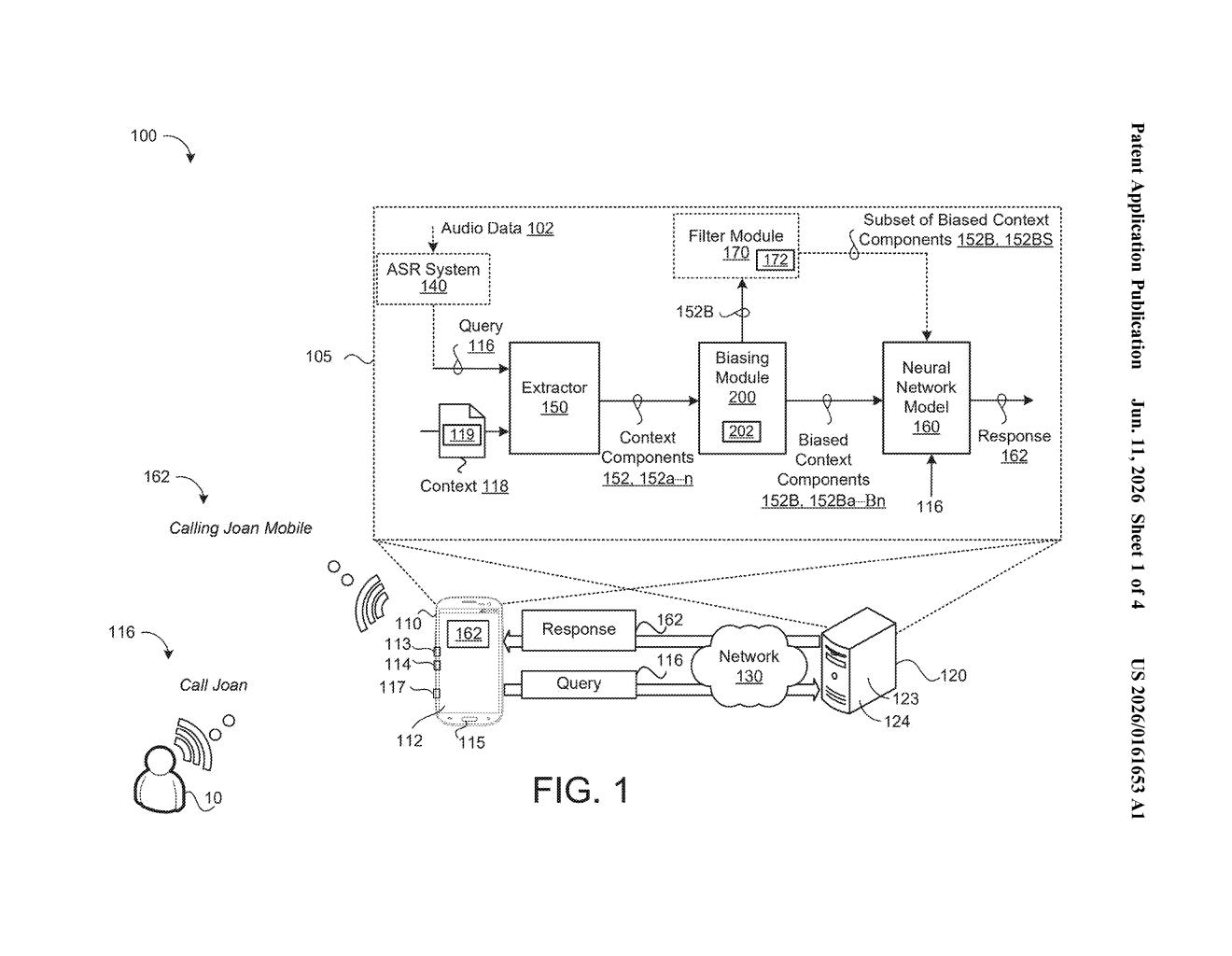
What Google's context-weighting AI actually does
Imagine asking your phone's AI, "What should I eat for dinner?" Your assistant has access to a lot about you: your location, recent messages, calendar events, health data. But most of that is irrelevant to tonight's dinner. Today, the AI often treats all of it roughly equally, which can muddy the answer.
Google's patent describes a system that first scores each piece of background information by how relevant it is to your specific question, then turns up the volume on the useful stuff and turns down the noise before generating a response. Think of it like a sound mixer adjusting levels on different tracks before the final recording.
The whole process is designed to run directly on your device — no round-trip to a remote server. That matters for speed and privacy, since your personal context never has to leave your phone.
How the model scores and biases each context piece
The patent describes a pipeline with three core steps:
- Context decomposition: The system breaks incoming context (background information tied to your query) into discrete components — think individual data points like your current location, a recent calendar entry, or a previous message in the conversation.
- Priority scoring: Each component gets a relevance score that reflects how closely it relates to the current query, relative to all other components. This is a comparative ranking, not just a pass/fail filter — so the system understands that one piece of context is more useful than another, not just that both exist.
- Biasing (weighting): Each context component is then amplified or dampened based on its score before being fed into the neural network. Higher-priority context has more influence over the final response; lower-priority context is effectively quieted.
The neural network model — running locally on the device — then generates its answer using this pre-weighted context rather than a raw, unfiltered pile of background information. The claim specifically calls out that the scoring is comparative across components, which is the key engineering distinction here: it's not enough to know a piece of context is relevant in isolation; the system needs to know how relevant it is compared to everything else it has access to.
What this means for on-device AI assistants
On-device AI assistants are only as good as their ability to stay focused. A system that can't tell your gym schedule from your dinner plans from your commute history is going to give you generic, low-quality answers. By teaching the model to rank context before reasoning, Google is targeting one of the core failure modes of personal AI — context overload.
The on-device emphasis is the other meaningful detail. Running this ranking and weighting process locally means faster responses and less data leaving your phone. That's increasingly important as AI assistants get access to more personal information, and as regulators worldwide pay closer attention to what cloud-based AI does with user data.
This is the kind of unglamorous infrastructure work that actually determines whether AI assistants feel sharp or sluggish in daily use. Context ranking is a real problem, and patenting a comparative weighting approach for on-device models is a specific, defensible engineering choice — not a broad AI land-grab. Worth paying attention to, especially as Google pushes Gemini Nano further into Pixel devices.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.