Google's New Patent Teaches AI Images to Keep Their Story Straight
Most AI image generators treat every part of a picture the same way. Google is patenting a method that lets different regions of an image "talk to each other" during the generation process — so the final result holds together more coherently.
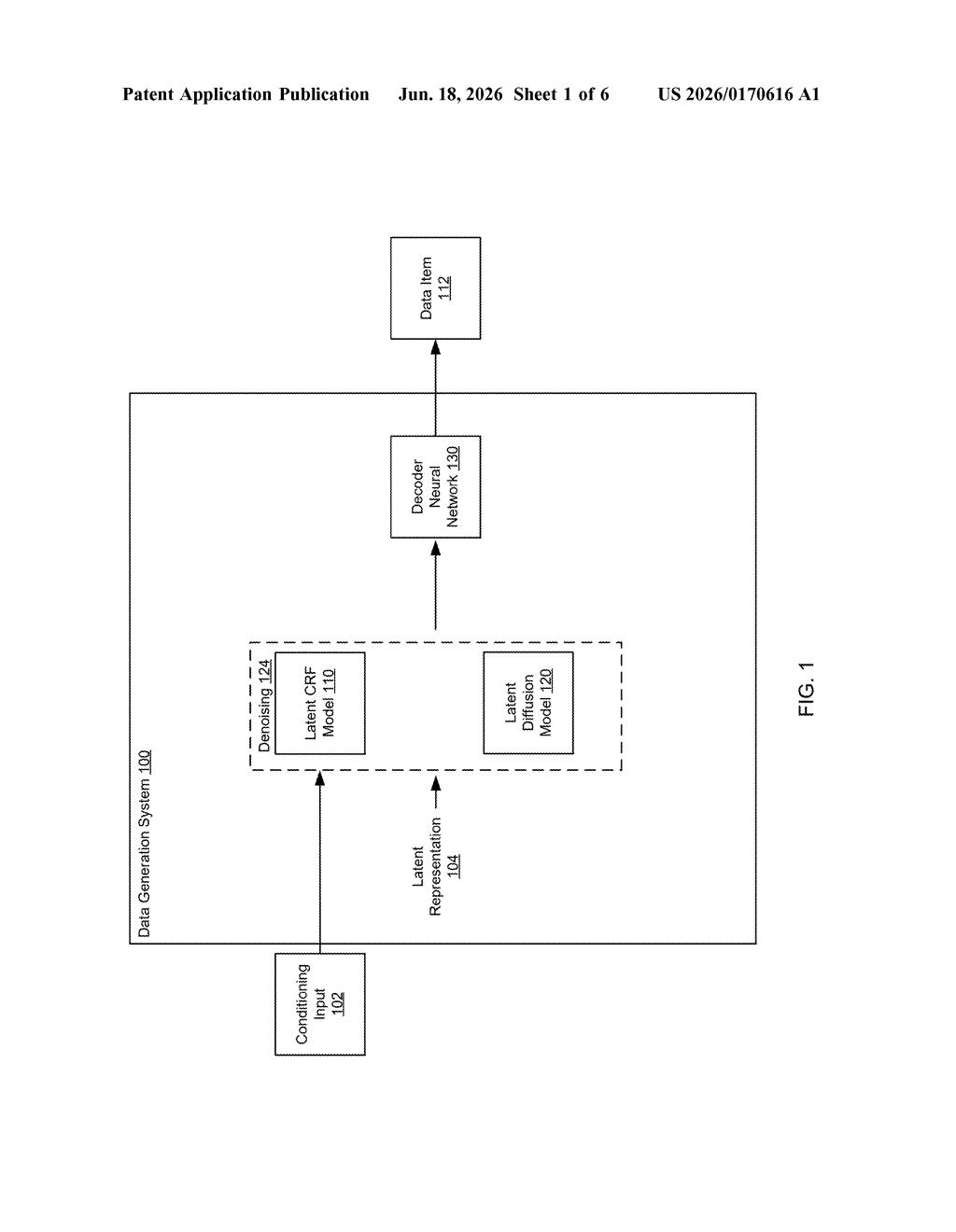
What Google's random-field image generation actually does
Imagine asking an AI to paint a photograph of a dog sitting on a red couch. Current AI image tools work by starting with pure noise and gradually cleaning it up, step by step, until a picture emerges. The problem is that each tiny region of the image can end up looking fine on its own, but neighboring regions don't always agree with each other — you might get a dog leg that doesn't quite connect to the body.
Google's patent describes a fix: at key points during that cleanup process, a special model checks how each region of the image relates to the regions around it, then nudges everything so the parts are consistent with one another. Think of it like a copy editor reading a paragraph for internal contradictions, not just spell-checking word by word.
The same technique applies to video and audio, not just still images. The idea is to bake spatial (and potentially temporal) consistency directly into the generation process, rather than patching problems up after the fact.
How the CRF model reshapes each denoising step
Standard AI image generation works through a process called diffusion: the model starts from random noise and runs through dozens of "denoising" steps, each one making the image a little cleaner and more defined. Each step typically processes the image as a grid of compressed numeric vectors — a latent representation — without explicitly modeling how neighboring positions relate to each other.
Google's patent inserts a latent continuous conditional random field (CRF) model at select points in that denoising sequence. A CRF (conditional random field) is a well-established statistical tool that models the probability of a value at one position given the values at neighboring positions — essentially, it encodes the rule "adjacent regions should be compatible with each other."
By applying this CRF inside the latent space (the compressed numeric representation, not the final pixel grid), the patent describes a way to:
- Initialize a grid of latent vectors from a conditioning input (a text prompt, a reference image, etc.)
- Refine those vectors across denoising steps, with occasional CRF passes that enforce local consistency
- Pass the final refined latent representation through a decoder network to produce the output image, video, or audio
The conditioning input is flexible by design — it could be a text description, a partial image, or any other signal that characterizes what the output should look like.
What this means for AI-generated images and video
Consistency across an image — or across frames of a video — is one of the most persistent weak points in today's AI generation tools. Hands with the wrong number of fingers, backgrounds that shift between video frames, text that warps mid-word: these are all symptoms of a generator that handles regions independently. A method that bakes neighbor-awareness into the generation loop directly addresses that class of failure.
For Google, this fits squarely into its work on Imagen and other generative AI products. If the technique holds up in practice, it could mean more structurally coherent outputs without requiring users to prompt-engineer their way around artifacts — a practical improvement for anyone using AI-generated visuals in real work.
This is a technically solid patent targeting a genuine problem — not a flashy capability claim but a quiet architectural fix. CRFs are an older, well-understood tool being applied in a newer context, which is a good sign for actual implementation. Whether the improvement in coherence is large enough to matter in production is the real question, but Google's research team has published in this area, so this isn't vaporware.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.